2020年9月3日、株式会社ジールにて、『【ウェブセミナー】大量データ活用の課題をクラウドサービスSnowflakeで解決!! ~国内3年前よりSnowflakeインテグレートをしてきたSolutions Architectに迫る~』が開催されました。その内容をレポートします。
昨今データ分析の課題として、大量データの処理がしきれない、BIなどからの同時クエリ数が増えすぎて、レスポンスが担保できない等々の課題が、世界中のお客様で増えております。
その解決策の一つとして注目されているのが『Snowflake』です。3年前より『Snowflake』を国内で取り組まれてきた第一人者であるSnowflake株式会社の本橋氏と、Business Analytics分野において 20年の実績を持つ株式会社ジールのAnalyticsスペシャリストの石家氏が、現在の国内での状況から、具体的に取り組まれてきた課題、導入したお客様からの評価などを、対談形式で迫っていくと共に、皆様の疑問にお答え致します。
講師紹介
Snowflake株式会社 Solutions Architect 本橋 峰明氏
株式会社ジール 上席チーフスペシャリスト 石家 丈朗氏

目次
2.データ活用の課題①
「データが分散しているため、データ統合をどのように進めたら良いかかが分からない」
3.データ活用の課題②
「世界各地のAWS 、 Azure にデータを分散させて、ガバナンスをかけながら活用したい」
「冗長システムを組めるか?」
「AWS と Azure 間でデータの差分同期などをかけることはできないか?」
4.データ活用の課題③
「データを集めたがデータの活用のしかたが分からない」
「データ活用基盤の構築を行ったが思ったより処理が遅くデータ活用までに至っていない」
「既存のDWH の環境では同時実行処理や、ディスク容量の制限などの課題が明確なため、
オンプレ環境からクラウド環境への移行を検討している」
5.データ活用の課題④
「同時実行によるBI ツールのレスポンスが悪く、利用制限を行いながらデータ活用を行っている」
「現行のDWH 環境よりもレスポンスや同時実行性の良いものを試してみたい」
はじめに
全社横断的なデータ活用の可否が企業の成功の鍵となりますが、社内外にまたがる多種多様な膨大なデータを残念ながら企業は活かしきれていないというのが現状ではないでしょうか?その理由としては、古くから課題として挙げられているシステムのサイロ化、日々増加する多種多様なデータ量、クラウド化、コンプライアンス対応 等々。
事前にデータ活用における課題をアンケートでいただいておりますので、各々の課題について、クラウドデータウェアハウスのSnowflake がどのように課題解決に貢献できるのかを、Snowflake社のエバンジェリスト 本橋様に聞いていきます。
データ活用の課題①
「データが分散しているため、データ統合をどのように進めたら良いかが分からない」
データをどこで管理するのか?ということが肝になります。グローバルな会社においてよくあるパターンとして、日本、EMEA、USの三拠点で展開しているケースがあります。どのデータをどの拠点が責任をもって準備するのか、拠点によって同じようなデータを扱っていてもデータの粒度が違ったりするので、組織によって進め方が変わってきます。完全に一つの統合したDWHを用意するのか、拠点ごとに利用者のDWHを用意して拠点間でリプリケーションをするのか、といった全体のアーキテクチャーは早いタイミングで決める必要があります。ワールドワイドで同時に開発を進めると、進捗が滞っているケースが見受けられます。どこかパイロット的に開発を行い、プロセスなどを確立した上、徐々に横展開していくのが現実的でしょう。
「Snowflakeでは、グローバルに散在するデータをETLを構築することなく、いろんなところで活用できるような製品だと思ってるんですけれどもいかがですか?」
と、いったご質問をいただいています。
Snowflakeは、グローバルに散在するデータを集約して、活用することができます。ただし、ETL(ELT)といわれる処理は必要になります。
ここでSnowflakeを活用した時のデータフローを説明いたします。
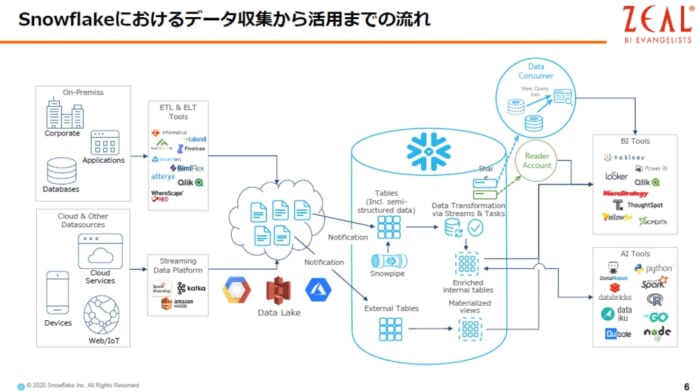
①Snowflakeは、Azure、GCP、AWSなどすべてのクラウドで動くDWHになっているため、クラウドストレージからデータを、簡単にロードできる仕組みとなっています。
また、クラウドの違いはSnowflakeが吸収していますので、お客様はどのクラウド上のSnowflakeでも同じようにお使い頂くことができます。
②SnowpipeとよばれるサーバーレスなETL機能があります。これは、クラウドストレージにファイルが保存されるとその瞬間に自動的に必要なコンピュータリソースが立ち上がり、ロードしてくれます。ロードが終わると自動的に停止してくれるフルマネージドのサービスです。
③また、データをロードせずに、クラウドストレージを直接参照する機能もあります。外部テーブル(External Tables)という機能です。またパフォーマンスを出すためにマテリアライズドビュー(Materialized Views)を作成することも可能です。
④次にデータをSnowflakeに取り込んだ後、データを活用するためには、加工する必要がありますが、Snowflakeでは、ストリームとタスクという機能がそれに該当します。ストリームは、いわゆるChange Data Capture の機能で、テーブルがインサートされたのか、アップデートされたのかデータがデリートされたのかを管理し、タスクはスケジューラーの機能になります。
タスクを定期的に実行し、テーブルに変更があった場合にのみ、タスク内に定義されている加工処理が実行されることになります。
これらの機能を活用することによって、ターゲットテーブル(Enriched internal tables)を作っていきます。
このターゲットテーブルに対して、BIツールなどから参照することができるようになります。
データ活用の課題②
「世界各地のAWS 、 Azure にデータを分散させて、ガバナンスをかけながら活用したい」
「冗長システムを組めるか?」
「AWS と Azure 間でデータの差分同期などをかけることはできないか?」
Snowflake には様々なデータ共有の仕組みがあります。ひとつ特徴的なものとして、DataSharing という機能があります。
従来、AさんからBさんへデータをコピーしていたようなことも、Snowflakeでは、データの権限を設定するだけでわざわざ同じデータの複製をすることなく、利用させることができます。リージョンが異なる場合は、物理的な距離が発生するので、レプリケーション(同期)する必要がありますが、レプリケーションした後は、権限の設定だけで共有ができます。
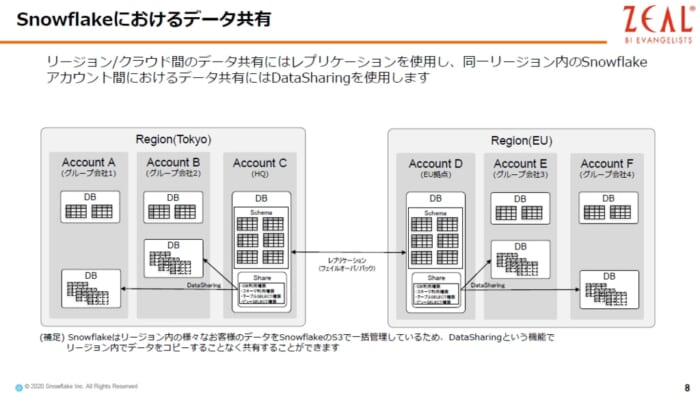
レプリケーション、フェイルオーバ/バックについては、同一クラウドのクロスリージョン間だけでなく、AWS、Azure、GCPといったクラウドを跨いで構築することもできます。これはSnowflake特有の強みですし、高い可用性、耐障害性を実現できます。
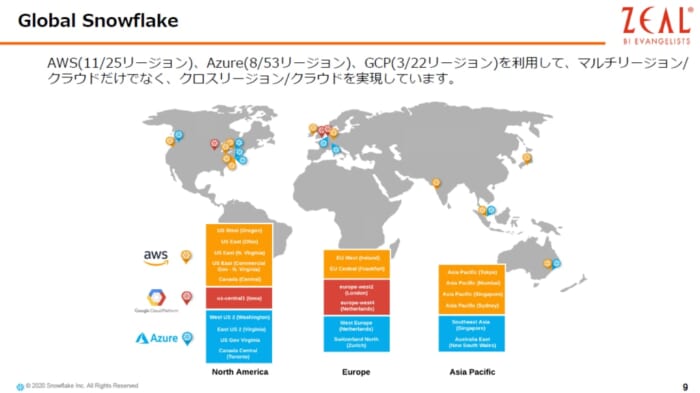
Snowflakeは、AWSでは11リージョン、 Azureでは8リージョン、 GCPでは3リージョン、合計で20以上のリージョンという環境で稼働しており、今後も増やしていく予定です。
データガバナンスという観点については、Data Masking という機能があります。Snowflakeでは、データが暗号化されて保存されていますが、それだけでなく、ロール(権限)によってデータをマスクすることができますし、さらには、サードパーティーの製品、例えばProtegrityという製品を使うことによって、データを保存するときに匿名化し、参照する際に透過的に取り出すこともできます。
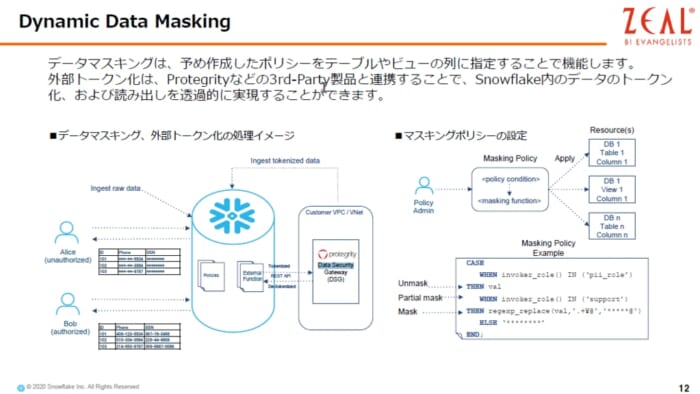
誰もが利用できる利便性を求められますが、同時に安全な形で使えないと使われなくなってしまいますので、大変有効な機能です。
データ活用の課題③
「データを集めたがデータの活用のしかたが分からない」
「データ活用基盤の構築を行ったが思ったより処理が遅くデータ活用までに至っていない」
「既存のDWH の環境では同時実行処理や、ディスク容量の制限などの課題が明確なため、オンプレ環境からクラウド環境への移行を検討している」
事業部門やシステム部門でデータがどのように使われているのか調査した上で、最終的に自社が抱えている課題が何なのか?それに対してどういう分析をする必要があるのかを把握する必要があります。いわゆるデータマネージメントの領域で、自分たちがどのように活用していくかを考えていかなければなりません。また、ずっと同じ状態ということはないので、社内の体制を整え、プロセスを管理し、継続して調べていくことも必要です。
データ活用基盤の処理が遅く、データが活用されないという状態については、まず、なぜ遅いのかを把握する必要があります。ネットワークの問題か、DWHの問題なのかなど。よくDWHの性能が出ていないということもありますが、それは、利用状況のピーク時を考慮して構築されていないことが原因です。つまり、自由にコンピュータリソースが使えないというケースです。
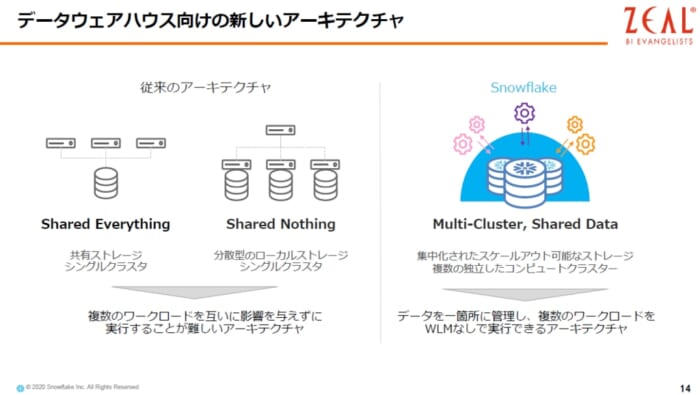
Snowflakeは、ワークロードにクラスターを割り当てる形で、そのクラスターが伸縮自在で、コンピュータリソースを大きくしたり小さくしたりできるので、うまく処理性能が出ないということが起きない仕組みになっています。このような機能を利用してデータ分析基盤を作っていけば、悩まず構築できます。つまりサイジングの失敗を防ぐことができます。
Snowflake の仕組みとして、コンピュータとストレージが完全に分離しており、ディスク容量の制限もなく、コンピュートリソースも競合しません。ワークロード同士が競合しないというのが大きな特徴になっています。例えば、BIのワークロードとETLのワークロードが競合してしまうので、処理完了をたないといけない仕事をするというケースがありますが、Snowflakeでは、そのようなことを心配する必要は一切ありません。
データ活用の課題④
「同時実行によるBI ツールのレスポンスが悪く、利用制限を行いながらデータ活用を行っている」
「現行のDWH 環境よりもレスポンスや同時実行性の良いものを試してみたい」
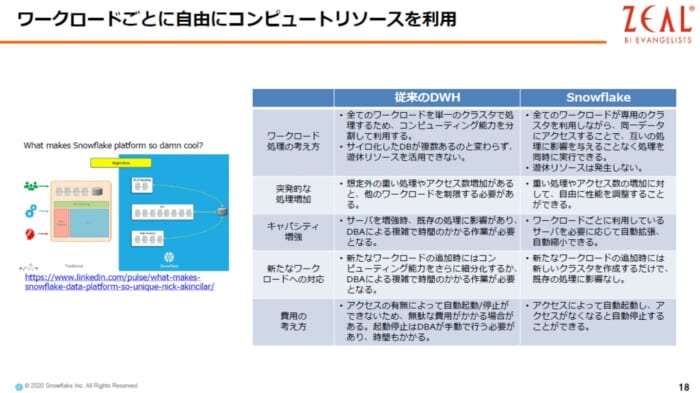
従来のDWHはコンピュートリソースの伸縮性に欠けるので、コンピュートリソ=スは基本的には赤い線のように直線になりますが、実際の時に、赤い線をはみ出したワークロードは、リソースが足りなくなっています。逆に、赤い線に満たない白い部分は、利用せずに余らせている状態になります。
その点、Snowflakeは、下記の図の水色線の通り、必要な時に必要な分だけコンピュートリソースを用意することができるので、無駄なコストがかかりません。また、ユースケースとして、BI系のユーザーが週明けに同時にたくさんアクセスしてくるということがありますが、そのような時間帯だけコンピュートリソースを増やすことができます。しかもSnowflakeでは、コンピュータリソースのスペックは、瞬間的に変更することが可能です。同時実行に至っては、制限がありません。トランザクションを実行することも可能です。
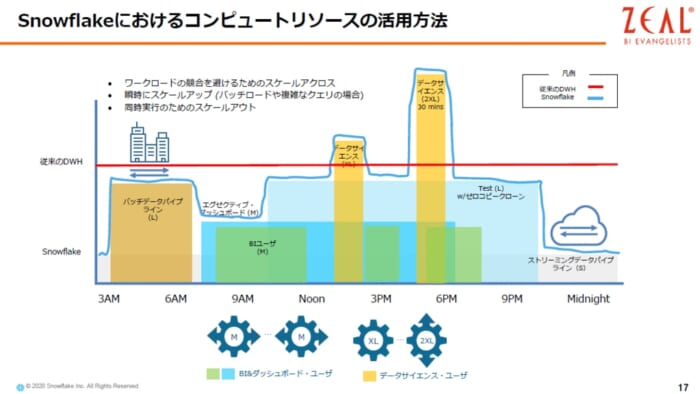
以下の図は、Snowflakeが従来のDWHと異なっているところを纏めたものになります。
無料トライアルの紹介
Snowflakeのアカウントを作成頂くと、30日間で400ドル分を無料でSnowflakeをお使い頂けます。Snowflakeアカウントには、10TB、約2800億件入ったテーブルなど、TPC-DS、TPC-Hのデータセットとクエリが用意されていますので、大量データを使ったパフォーマンスの検証をすぐに始めることができます。また、使い方から試したい方のためのハンズオンラボガイドを用意していますので、従来のデータウェアハウスに課題をお持ちの方、もしくは、これからデータ分析基盤の構築を検討している方は、ぜひお試しください。
■無料トライアル
30日間の無料トライアルを開始する
サインアップで400ドル相当を無料で使用できます。
■ ハンズオンラボガイド
ガイドに沿って操作するだけで、Snowflakeの特徴を 90分でご理解頂けます
https://www.snowflake.com/resource/snowflake-free-trial-lab-guide-japanese/
まとめ
Snowflakeの創業者は、オラクルにいた技術者ですが、クラウドベースでDWHを統合できる製品を作りたい強い気持ちから、スクラッチで作り上げたという背景があります。DWHが散在し、データ統合に困っているお客様にとって、Snowflakeは、最適なソリューションとなる製品です。
もっと聞きたい、知りたいと考えている方は、下記からお問い合わせください。
・Snowflake
https://www.zdh.co.jp/products-services/dwh/snowflake/