2024年6月4日(火)、5日(水)、日経BP 総合研究所 イノベーションICTラボ 日経ビジネス、日経クロステック主催の「DX Insight 2024 Summer」がオンラインで開催され、DX銘柄選出企業の事例講演のほか、中堅・中小企業等のDX支援の在り方に焦点を充てた講演が行われました。
今回ジールは「生成AI活用を見据えたモダナイズ、クラウド戦略の再構築」にプラチナスポンサーとして協賛し、弊社瀧澤が講演を行いました。その模様を突撃隊長ウエムラが受講し内容をレポートします。
目次
開催概要
イベント名 : DX Insight 2024 Summer
日時 : 2024年6月4日(火)、5日(水)
会場 : オンライン
主催 : 日経BP 総合研究所 イノベーションICTラボ 日経ビジネス、日経クロステック
https://events.nikkeibp.co.jp/event/2024/nb24060405/
「経営課題解決シンポジウムPREMIUM DX Insight」は経済産業省が2018年9月に発表した“DXレポート~ITシステム「2025年の崖」の克服とDXの本格的な展開~”を受けて、日本企業のDX推進の機運を高めるねらいで毎年2回開催してきた日経BPの人気オンラインセミナーです。
今回は、「生成AIを見据えたモダナイゼーション、クラウド戦略の再構築」をテーマに、2030年以降の成長と発展を目指すイベントとして開催されました。
ビジネスシーンで生成AIを本格活用するために必要なデータ基盤の在り方とは?
今回の「DX Insight 2024 Summer」では弊社ジールのCTO、瀧澤祐樹さんによる講演が行われました。
ビジネスシーンで生成AIを本格活用するために必要なデータ基盤の在り方や、より多様なデータ活用を成功させる上で効果的なデータ基盤とはどのようなものか
ということが本講演のメインテーマです。
従来型のデータ基盤との違いと併せて解説した講演の内容を、隅々まで本記事でレポートしますので、ぜひ最後までお読みいただけたら嬉しいです。
講演者紹介
瀧澤 祐樹
株式会社ジール
執行役員 CTO
デジタルイノベーション領域統括

出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
生成AI(LLM)の登場により「データ」の価値がますます向上する現代
まずは何を置いても「生成AIとは?」というお話からです。
生成AIとは、本講演では「大規模言語モデル(LLM)」としています。
そして、私たちが簡単にブラウザ上で使用できる「ChatGPT」のように、何もカスタマイズしていない「大規模言語モデル(LLM)」を「バニラ」といい、そのままでも便利で使い勝手のよいツールです。
しかし、ビジネスシーンで本格的に生成AIを活用するためには、それだけでは足りないそうです。
非常に巨大なデータセットとディープラーニング技術を用いて構築された言語モデルのこと。
出典:NRI.「大規模言語モデル」https://www.nri.com/jp/knowledge/glossary/lst/ta/llm
瀧澤さん:生成AI とひと言で申し上げていますが、LLM 大規模言語モデルと読み替えていただければと思います。生成AIは昨年あたりから徐々に市場に出回り、社会に与えたインパクトは大きかったと思います。
何もカスタマイズしていないLLMを「バニラ」と呼びますが、みなさんの日々の生活においても大小さまざまな回答を生成AIが返してくれます。
このインパクトを最大限に発揮し、普段の業務を高度化させるためにはデータが不可欠です。
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
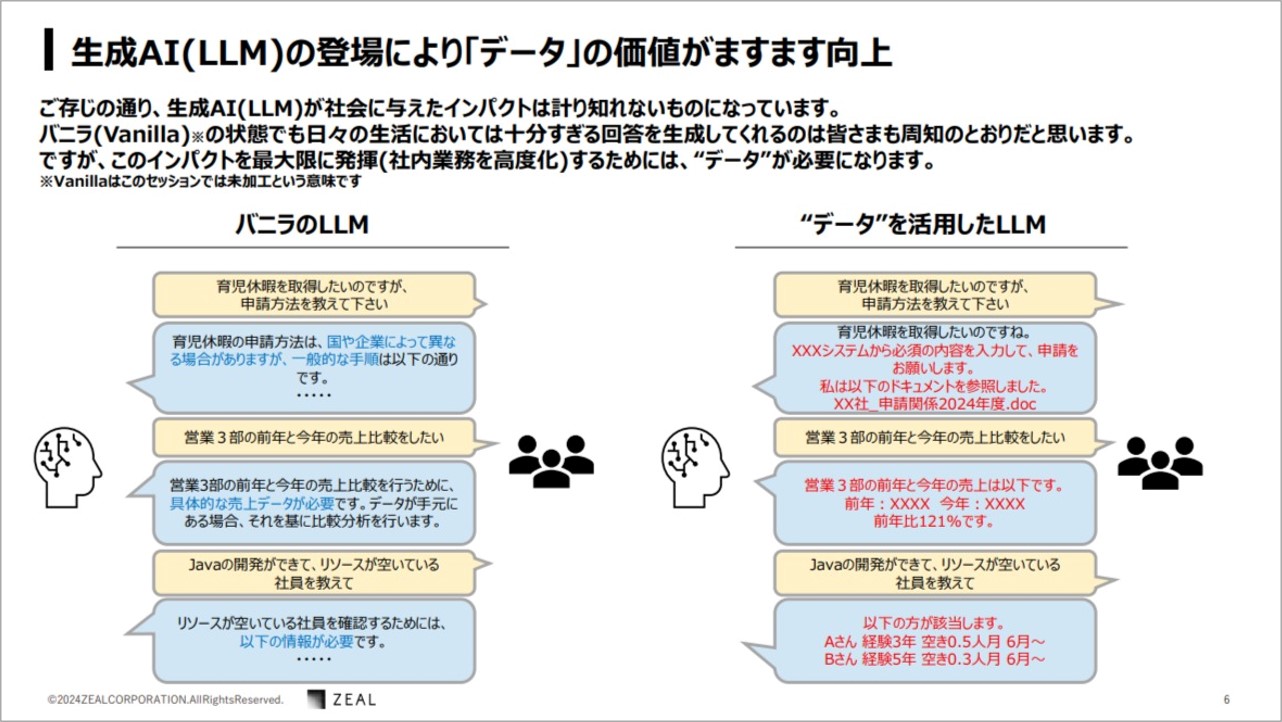
瀧澤さん:例えばバニラの LLM に対して、「育児休暇を取得するための、申請方法を教えてください」と利用者が質問をした場合、一般的な手順の説明を返します。
しかし利用者は、「自分が勤めている会社の育児休暇取得方法」を知りたかったため、解答としては不十分です。
データを活用したLLMは、質問をするとシステムから必要な必須の内容を入力して申請情報と、ドキュメントを確認した旨のコメントとリンクを添えて回答します。
LLMは、質問者の意図を理解して必要なドキュメントにアクセスし、回答を生成しています。
生成AI(LLM)活用のロードマップ
このように、バニラの LLMのままだと、所属する企業の「育児休暇」の社内ルールではなく、世間一般的な「育児休暇」に関する内容しか生成AIは返してくれません。
そのため、社内の基幹データを読み込んで、自社の規則に沿った回答を生成AIが返すようにする必要があります。
その手順が以下のロードマップで解説されています。
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
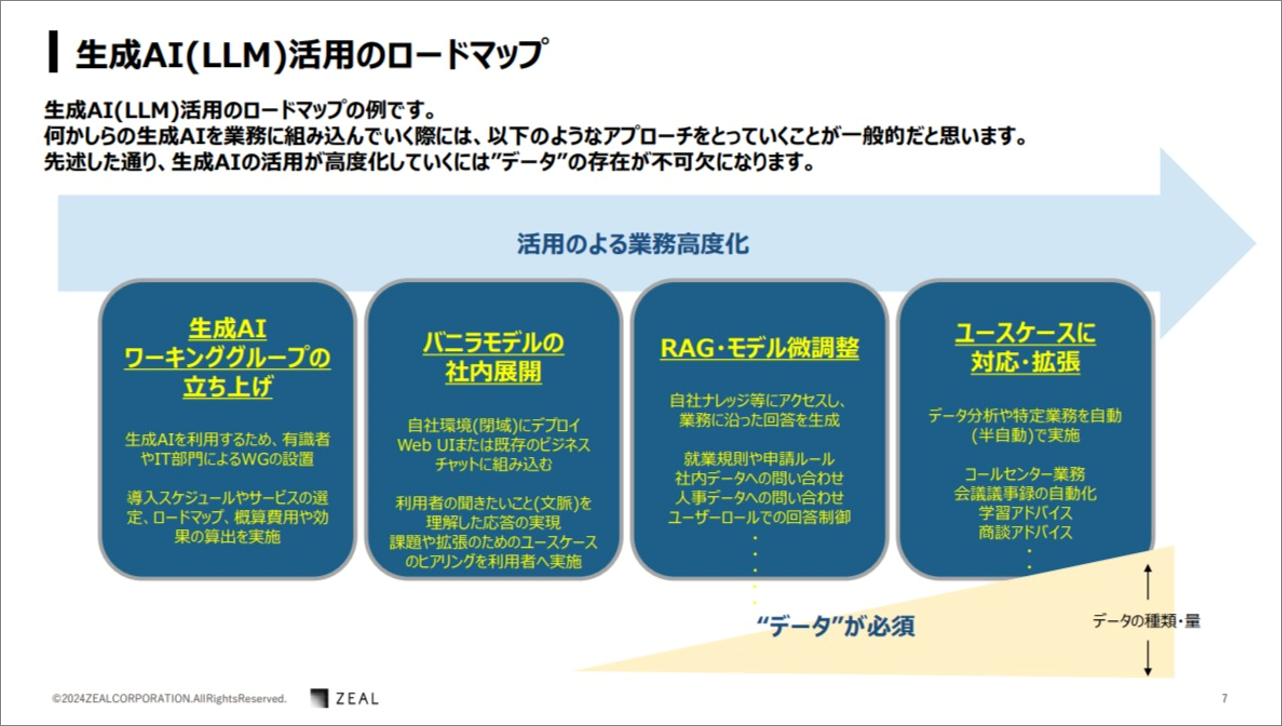
瀧澤さん:生成AI活用のロードマップの一般例をご紹介します。
上の図の水色の矢印は左から右に伸びています。これは生成AIの活用に伴う、業務の高度化を表しています。
ステップ1:生成AIワーキンググループの立ち上げ
瀧澤さん:はじめに、生成AIワーキングループの立ち上げにおいて、社内外の有識者や、自社の IT 部門の担当者などのメンバーで構成されます。
このフェーズでは、ワーキンググループの設置、導入、スケジュール管理、利用するサービスの選定、ロードマップの策定、コスト管理などを行います。またPoCを行うことで、差別化のポイントを認識することもできます。
ステップ2:バニラモデルの社内展開
瀧澤さん:次のステップとして、バニラモデルの社内展開を行います。基本的には、自社環境においてネットワークの中でモデルをデプロイします。
テストユーザーは、トライアルのような感覚で利用できます。
そうすることで前のフェーズで行った計画をより具体化していくことになります。
ステップ3:RAG・モデル微調整
瀧澤さん:その後、RAG・モデルの微調整として業務に沿った回答や自社ナレッジ、自社用にカスタマイズした回答を生成できるフェーズになります。
データにアクセスし、質問に対する回答を生成する過程で、精度チェックの機能を用意して調整しますが、当然センシティブなデータも含まれますので、ユーザーロールでの回答制御もこのフェーズで考慮する必要があります。
ステップ4:ユースケースに対応・拡張
瀧澤さん:そして、ユースケースに対応・拡張においては、ある特定の業務を自動もしくは半自動で実施していくフェーズになります。
上記のステップ1~4の手順を踏むごとに、生成AIを組み込んだデータ活用レベルは高度化していきます。
生成AIを組み込んだデータ活用がより高度化することで、例えば、あるお客様のところへ商談に行く際に、これまでの取引実績や商材の情報を学習させることもできるようになるそうです。
生成AIが商談に最適なアドバイスを生成してくれるようになるとのこと…すごい時代です。
欲を言えば、前回は担当者とこんな雑談をして、こんなことに興味があったなど、パーソナルな面も学習させておくと、次回のアイスブレイクのネタにも困らなそうですよね(笑)。
生成AI(LLM):データの蓄積と活用
次に、生成AI(LLM)とデータを掛け合わせて活用する際の「データの流れ」の解説になります。
生成AIを組み込まないデータ活用の場合、対象になるのは構造データがこれまでは主でしたが、生成AIを掛け合わせたデータ活用の場合は「非構造データ」にスポットライトが当たりやすいのが特徴です。
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
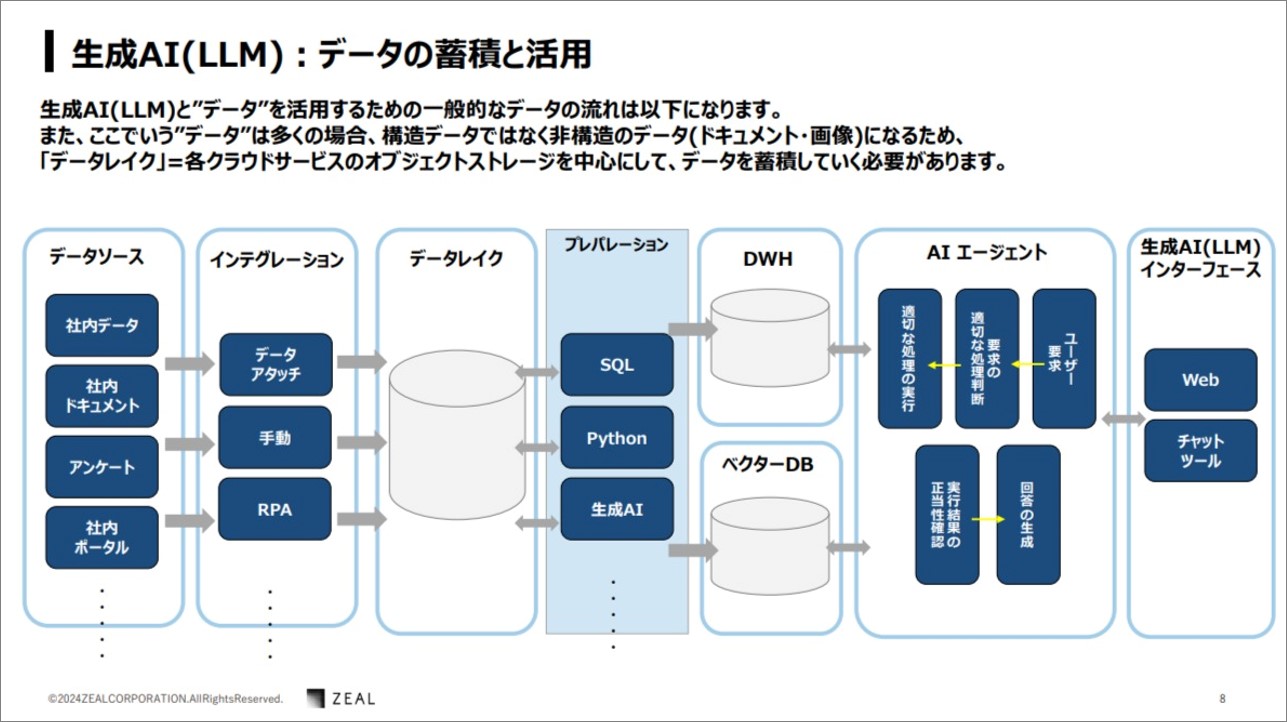
瀧澤さん:こちらは、生成AIにおけるデータの蓄積と活用について図式化したものになります。ここでのデータは構造データではなく非構造データになるケースが多いです。
非構造データとは、パソコンのマイドキュメントやダウンロードフォルダに格納されたドキュメントファイルやテキストファイル、パワーポイントやエクセル、画像などを指します。それらのデータを蓄積するためには、データレイクが必要になります。ある程度フローが確立したら、RPA などを使い自動化することも可能です。
データレイクに様々なフォーマットのデータが溜まりますが、それだけでは生成AI からの検索は難しいため、データウェアハウス、ベクターデータベースなど、生成AI の検索に特化したデータベースに格納する必要があります。そのため貯まったデータの文章の切り出しや、要約を行い、二次元のデータであれば、SQL で各々のデータベースに連携します。
一方、生成AI を使うためのインターフェースとしてWEBアプリ、普段お使いのビジネスチャットツールなどが該当します。AI エージェントと言われるRAG、ラングチェーン、そして各クラウドサービスが持っている AI サービスは、大きく以下の 5つの流れで回答を生成します。
2.要求の適切な処理判断
3.適切な処理の実行
4.実行結果の正当性確認
5.回答の生成
AIエージェントは、上記のようにユーザーからの質問を受け取り、一般的な質問か社内データに対する質問なのかを判断し、判断された処理を実行して正確性の確認を実施します。
問題なければ検索した結果を元に生成AIが回答を生成して返してくれます。
これらの手順を経て、世間一般的な回答ではなく、社内データに沿った適切な回答を返してくれるようになるのですね。
従来のよくあるデータ基盤
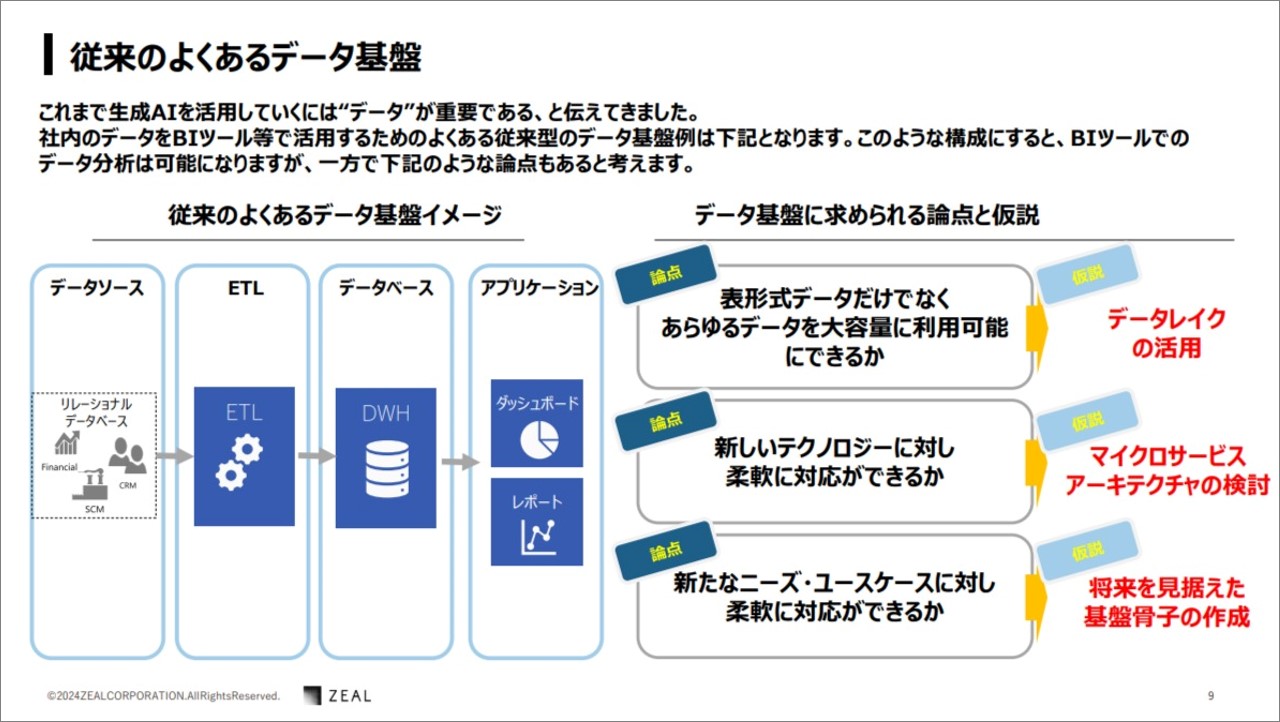
ここで一旦、従来のよくあるデータ基盤に立ち戻ります。従来のよくあるデータ基盤のままだと、今後どんなことが課題になりそうか?どんな未来が待っているのか?講演ではBI ツールを活用してデータ分析をした場合のデータ基盤を取り上げ、今後のデータ基盤に求められる論点と仮説が展開されました。
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」(2024/6/4DX Insight 2024 Summer資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」(2024/6/4DX Insight 2024 Summer資料)
瀧澤さん:これまで生成AIについてお話いたしましたが、ここからはBI ツールを活用しデータをレポーティングする構成の話になります。
ここで扱うデータは、基本的にリレーショナルデータベースで構成され、システムからETL ツールを使って、データベースに直接ロードします。そしてデータベースの中でダッシュボードや、レポートなど必要な情報を加工して、ユーザーに公開します。
AIやデータ基盤は、ニーズが多岐にわたっていますので、これからのデータ基盤に求められる論点と仮説を 3 つご紹介します。
<論点>表形式データだけでなく、あらゆるデータを大容量に利用できるか
<仮説>データレイクを利用
<論点>新しいテクノロジーに対して柔軟に対応できるか
<仮説>マイクロサービスアーキテクチャーの検討
<論点>新たなニーズ・ユースケースに対して柔軟に対応できるか
<仮説>将来を見据えた基盤骨子の作成
瀧澤さん:ケース1は生成AI で使うデータは非構造データになり、表形式データだけでなくあらゆるデータを大容量に利活用でき、新しいテクノロジーに対して柔軟に対応できるかが論点になります。
そしてケース2は、ケース1に対応するための仮説として、データレイクの活用とマイクロサービスアーキテクチャの検討です。
さらにケース3は、将来を見据えた基盤骨子の作成になります。
以上の3 点が、データ基盤に求められる仮説になります。
このように、現状うまくいっているBI ツールを用いたデータ活用についても、今後の未来にはどのような変化が起こり得るのか、ということを常に考察することが重要とのことで、既存のモデルにも最新技術を常時取り入れてアップデートしていくことが、今後もどんな業界でも必要不可欠なのだと感じました。
生成AI(LLM)を見据えたこれからのデータ基盤
さてここからは、本講演のメインテーマである「生成AIを見据えたこれからのデータ基盤」についての考察パートになります。
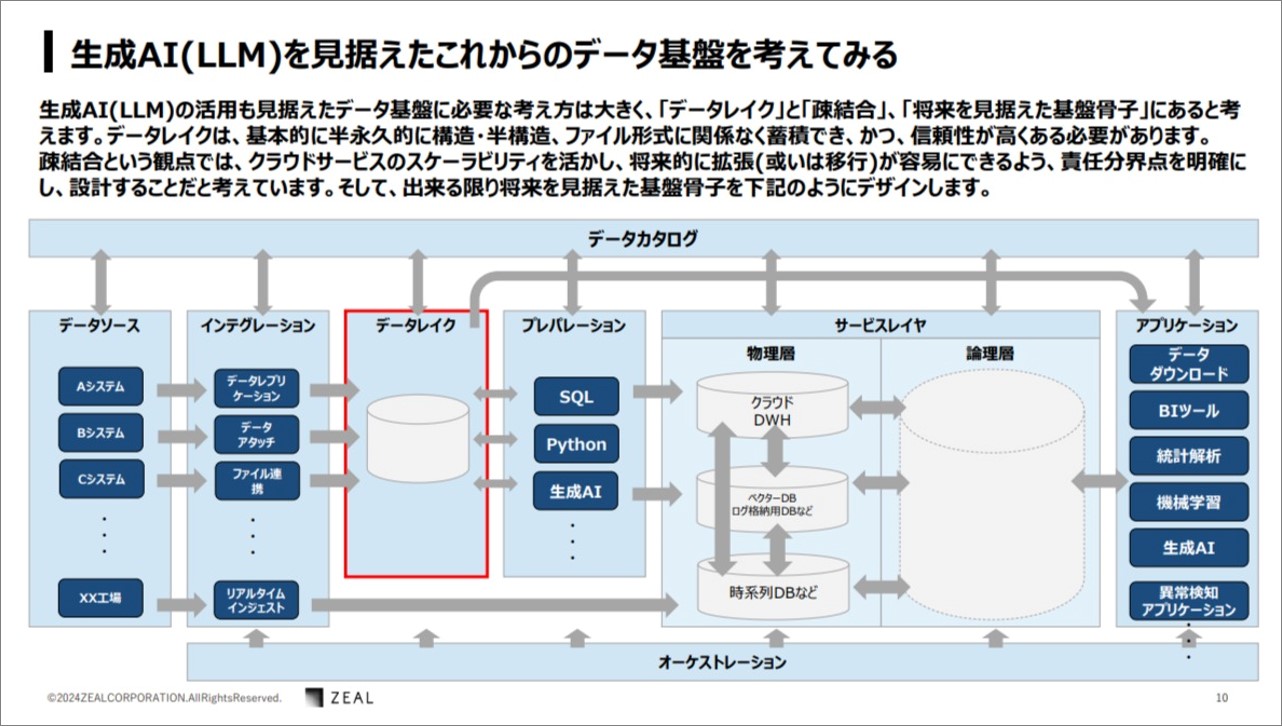
瀧澤さん:これからのデータ基盤は、データレイクとマイクロサービスアーキテクチャの疎結合、そして将来を見据えた基盤骨子を加味することが大切です。
それらを踏まえたデザインが下の図になるそうです。
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
ここで各領域についても瀧澤さんより説明がありました。下記に要点をまとめましたので、ご参考になれば幸いです。
データソース
インテグレーション
データレイク
データレイクのデータは、基本的には生データですので、活用するための準備としてプレパレーションの検討が必要になります。
プレパレーション
サービスレイヤ -物理層-
あるいはGPSのデータをリアルタイムで収集し、そこへアクションを起こしたい場合には「時系列データベース」が適しています。このように、活用ニーズに応じたデータベースを配置する必要があります。
サービスレイヤ -論理層-
アプリケーション
データカタログ
運用者はできる限り 1 つのサービスに集約したシンプルな設計にすることが重要になります。
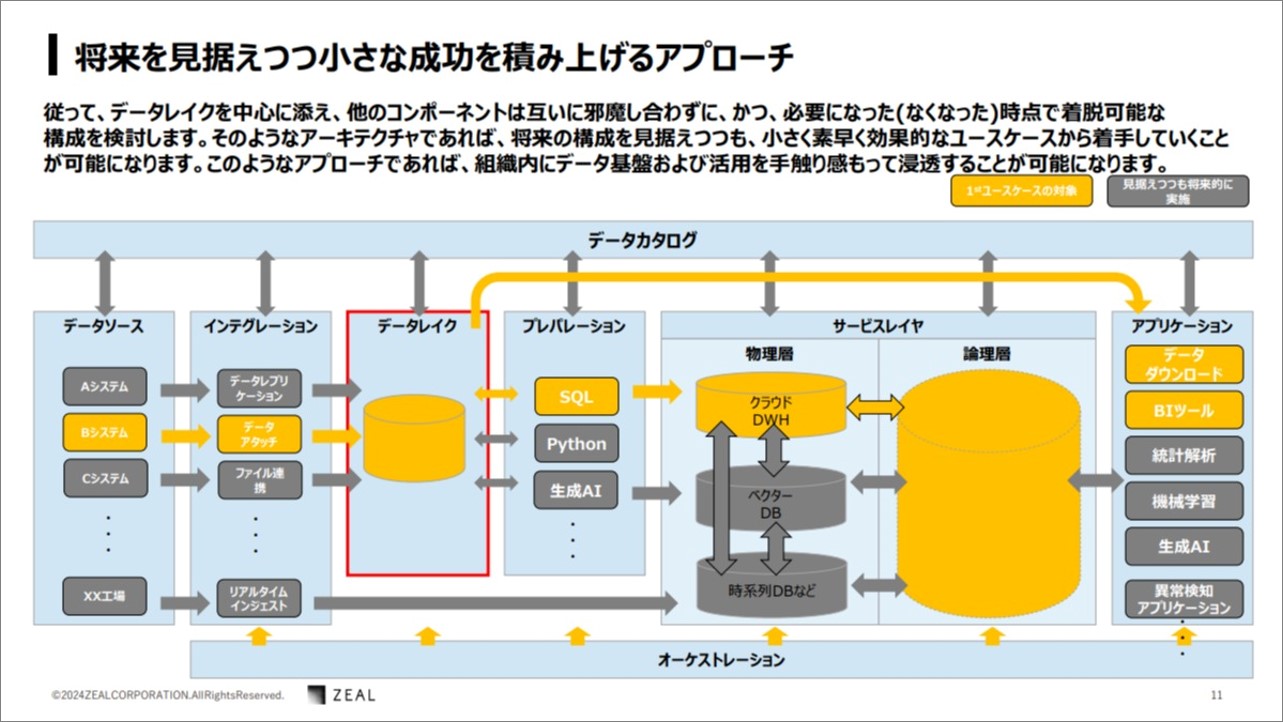
将来を見据えつつ小さな成功を積み上げるアプローチ
このように、将来を見据えたデータアーキテクチャであれば、小さく素早く効果的なユースケースから着手していくことが可能になるとのことです。
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
上図のポイントは、基盤の骨子を疎結合することでデータレイクを中心に、黄色の部分から着手するという点だそうです。
まずは必要最低限のコンポーネントを、必要可否に応じて着脱可能になるよう構成することで、「小さな成功を積み上げる」アプローチを行うのだそうです。
このようにしてデータの利活用を促進することで組織へのデータ基盤&活用が浸透しやすくなるとのこと。勉強になります。
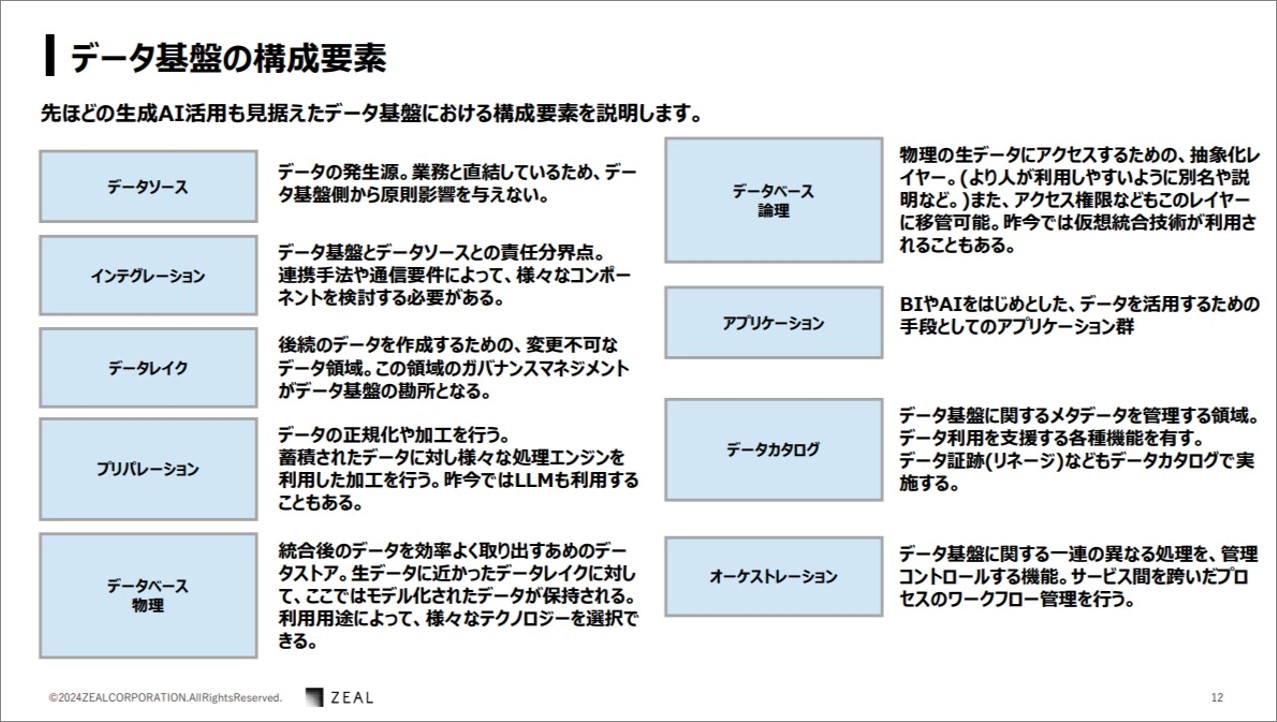
データ基盤の構成要素
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
さらに、データ基盤の構成要素は上記の通りです。
コンポーネント、データソース、インテグレーション、データレイク、プリパレーション、サービスレイヤーはデータベース物理層、データベース論理層、アプリケーション、データカタログ、オーケストレーションがあります。
ジールの支援サービス「データ基盤構想策定」について
講演の最後には、昨今のデータ活用の複雑化に対して、ジールの「データ基盤構想策定」サービスのご案内のお時間をいただきました。
データの価値が高まるにつれて、お客様より「どのように着手すべきかわからない」であったり、手順、導入方法についての相談を受けることが増えて参りました。
それらの課題を解決するためのサービス「データ基盤構想策定」にはどのような強み・メリットがあるのか、瀧澤さんからご紹介いただきましょう。
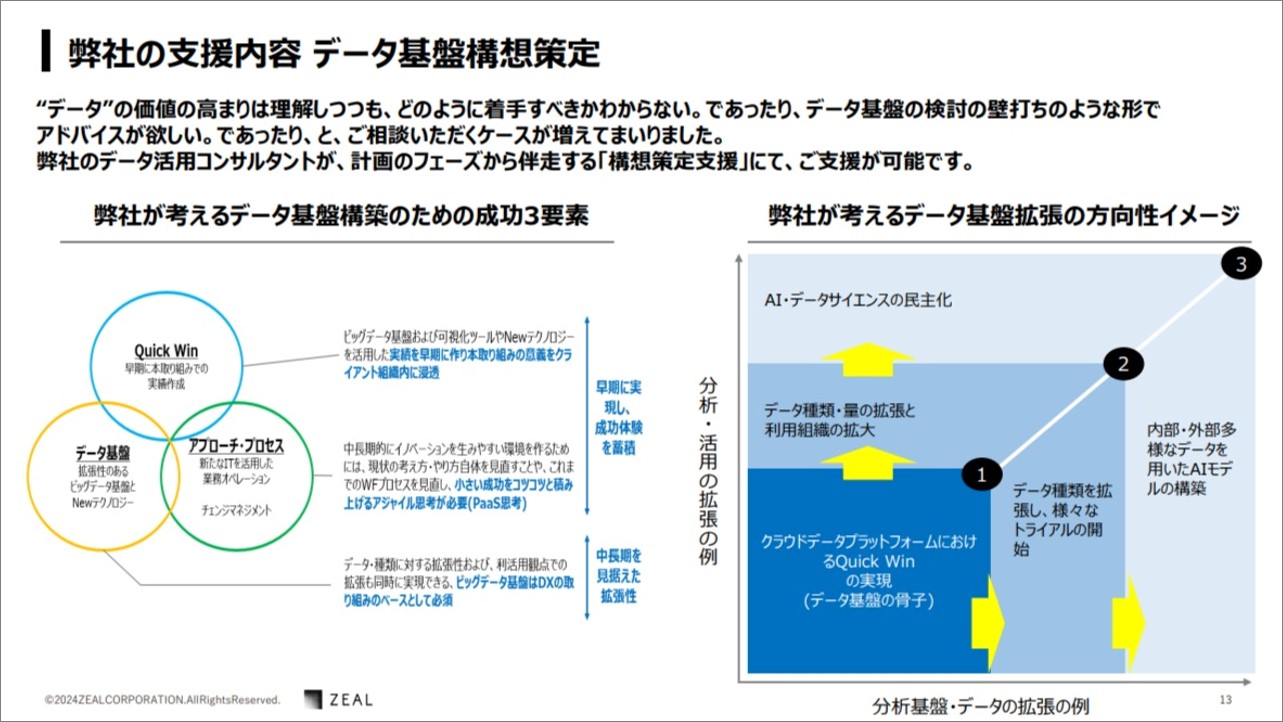 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
瀧澤さん:ジールでは、データ活用コンサルタントが構想策定支援を行い、お客様をサポートします。
ジールが考えるデータ基盤構築のための成功 3 要素は、「小さく始めて早期に結果を出す」というクイックウィンの考え方になります。データ基盤は導入しておしまいではなく、その後も進化させる必要があります。
アプローチ方法や、データ基盤の考え方をきちんと押さえつつ、データ基盤拡張のイメージをお客様とすり合わせ、伴走をしながらご支援するサービスです。
「データ基盤構想策定」サービスのサポート内容
この「データ基盤構想策定」サービスは、ある程度アセット化されておりますが、お客様の課題などによりカスタマイズも可能とのことです。
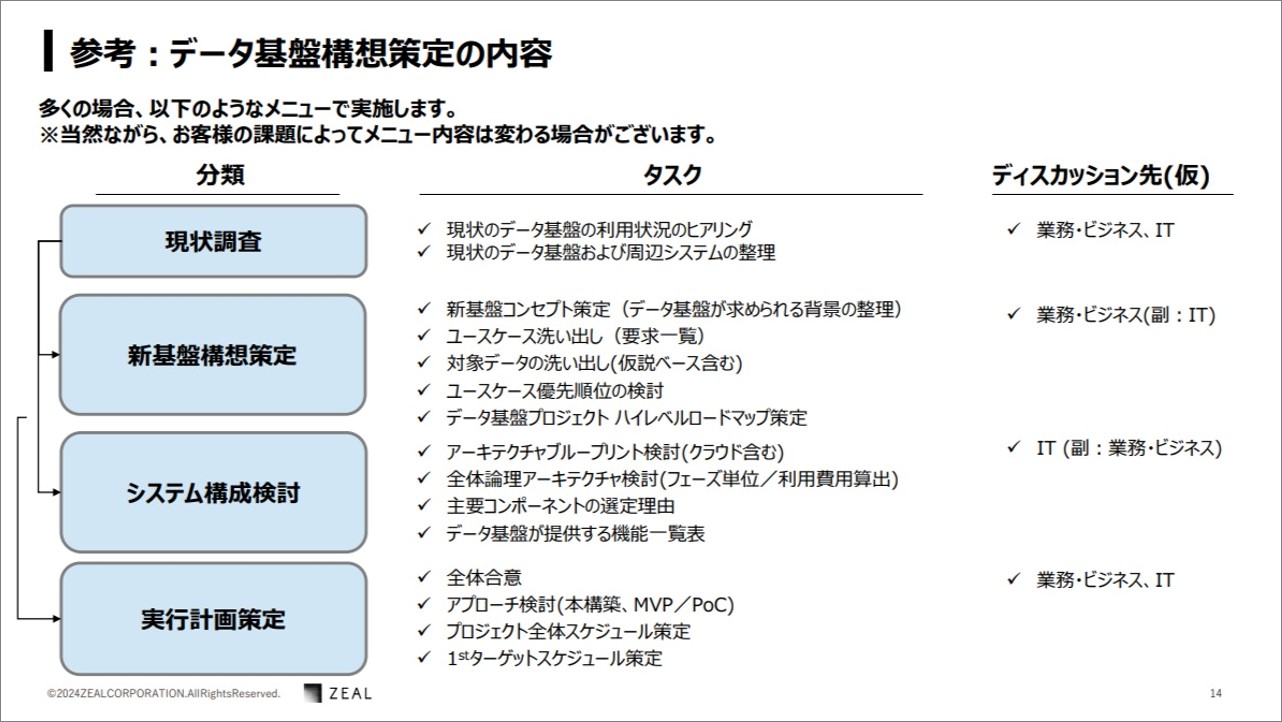 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
瀧澤さん:データ基盤構想策定は、「現状調査」、「新基盤構想策定」、「システム構成検討」、「実行計画策定」の4段階から構成され、 3~4ヶ月かけてお客様とミーティングさせていただきつつご支援いたします。さらに「データ基盤構想策定」サービスは、お客様の意見や意志を重視し、お客様に合ったデザインをご提案いたします。
アーキテクチャブループリント
併せて、「データ構想策定支援」サービスの中でこれまでに共同検討されたアーキテクチャブループリントについても紹介がありました。ホールディングス体制をとっている企業様の事例をもとに、アーキテクチャをご紹介いたします。
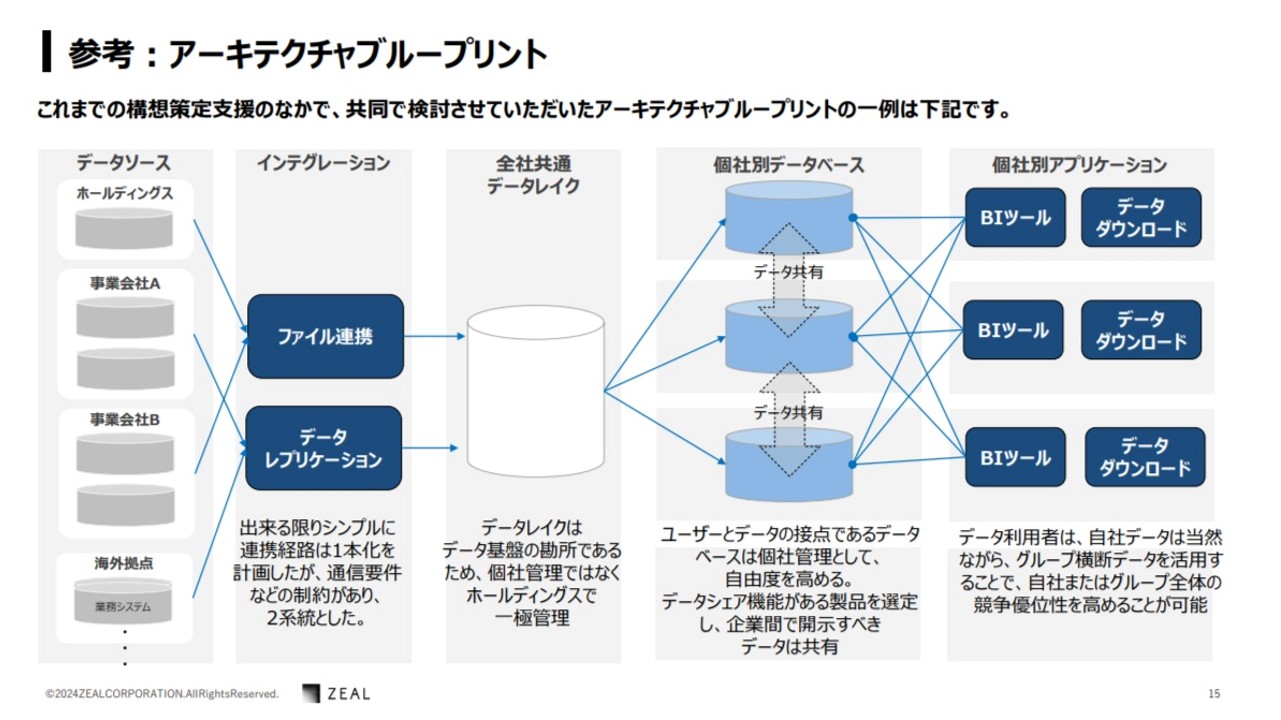 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
瀧澤さん:ご参考までに「データ構想策定支援」サービスの中で共同検討されたアーキテクチャブループリントについてご紹介します。データ基盤のデザインのベースを計画段階でアウトプットしたのち、実際にPoCや1stユースケースの構築が行われ、構想策定支援の期間の中で正式にデザインを行います。
上の図は、ホールディングス体制をとっている企業の構想策定図です。各事業会社が独自のデータ基盤を持っています。中期経営計画の DX戦略の中で、点だけでなく面でお客様に向き合い、サービス向上をめざした構想策定を行いました。
インテグレーションは、データの連携基盤として大きく 2 パターン検討しました。個社別にデータレイクを持つのではなく、全社共通データレイクを持ち、一極集中でホールディングスが管理する構想にしました。
そこから先の個社別データベースに関しては、ある程度自由度を持たせて運用しています。
顧客へのアプローチを点でなく面で行うためには、ある程度グループ内でデータ共有ができるようなサービスであることが必要です。
クラウド環境も事業会社ごとに、全く異なるものを使っているケースがありましたので、マルチクラウドで稼働できるようなデータベースを採択しました。
個社別アプリケーションに関しては、従来から使っているBIツールを引き続き利活用します。
上記の例のアーキテクチャは、全社共通データレイクを用いたり、グループ内でデータの共有を可能にしたことで、「点」でなく「面」でお客様のサービス向上を実現するアーキテクチャブループリントを策定した事例とのことです。
同様にホールディングス体制や複数のグループ企業を経営されている企業様の参考になる事例なのではないかと感じました。
構想策定後のステップ
本サービスは、「データ構想策定」だけではなく「データ構想策定後」も視野に入れ、以下の4つのステージの全てにおいてフォロー・伴走させていただく体制を想定しています。
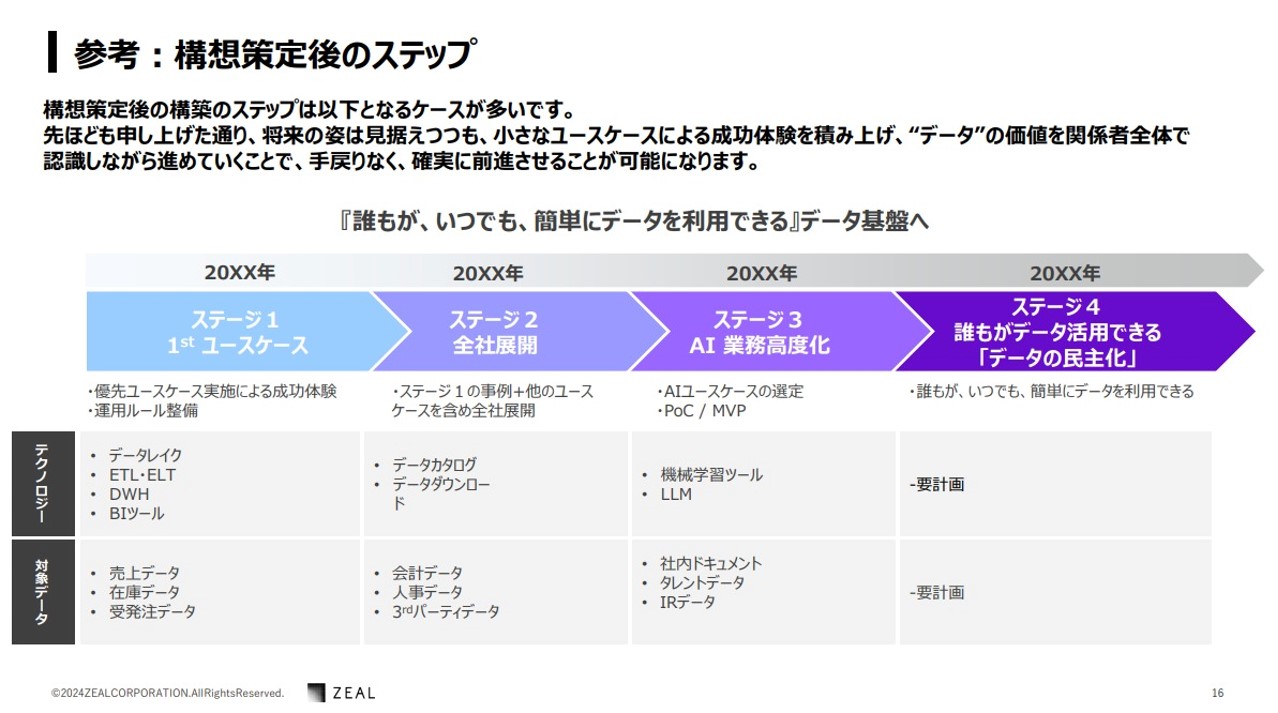 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
瀧澤さん:ステージ1は、1st ユ―スケースをスモールスタートし、特定のユースケースから始めて基盤の骨子を固めます。
ステージ 2 は、全社展開を行います。
ステージ3は、AI 業務高度化を目指します。
ステージ4は、誰もがデータを活用できるデータ民主化を目指し、より具体的な定義をして計画を策定します。
「データ構想策定後」のタイミングでは、基盤の骨子をきちんと関係者で理解することが重要になります。
関係者間で認識にブレが生じると手戻りや修正が発生しますので、基盤の骨子を着実に捉えて確実に前進させることが大切です。
データの価値が高まったからこそ「どのように着手すべきかわからない」という課題が発生するのは当然のことです。
ぜひ、少しでもお悩みの方は「データ構想策定」サービスはもちろん、ジールに気軽にお問合せくださいませ。
まとめ:生成AI(LLM)活用時代のデータ基盤の考え方
ここまでレポート記事をお読みいただきありがとうございます。最後に瀧澤さんのセッションのまとめで、締めとさせていただきます。
瀧澤さん:生成AI(LLM)の登場によってデータの利活用が多岐にわたり、また今後も加速していきます。今回のセッションでは、3つのポイントでデータの基盤のお話をお伝えしました。
●データレイクの重要性
●柔軟かつ適正なアーキテクチャの検討
●将来を見据えたデータ基盤骨子
この 3 点をきっちりおさえ、将来を見据えて小さく始めて成功を積み上げるアプローチがベストプラクティスだと考えています。課題をお持ちのお客様がいらっしゃいましたら、ぜひご相談いただければと考えています。このセッションが皆様のご検討の際の一助になれば幸いです。
 出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
出典:瀧澤 祐樹「生成AI活用時代だからこそ 最強で最高のデータ基盤を考える」 (2024/6/4DX Insight 2024 Summerセミナー資料)
瀧澤さん、ありがとうございました。
感想
生成AI、LLMが浸透する中で「データ」の価値に注目が集まる背景を受け、生成AI活用を見据えたデータ基盤の有用性を伝える内容でした。データレイクを採用することで、社内に分散しているあらゆる形式のデータを整理しながら格納し管理することは、重要な一歩を踏み出すことになります。
しかし、ただ格納しただけでは成功はしません。次に控えるアーキテクチャ、基盤の骨子の配置がデータの利活用を促進させる大きな分岐点となります。
「小さく始めて早期に結果を出す」というデータ基盤構築を推進させる考え方は、成功への近道だと思います。データ基盤を導入して満足していては、もしかすると宝の持ち腐れかもしれません。
導入後も自社にとってより使いやすい仕様へ変化させる必要があります。分散されたデータの配置ではなく、サービスに集約したシンプルな設計こそが成功の鍵だということもわかりました。
お気軽にご相談ください
ジールの支援サービスは、課題をお持ちのお客様、なかなか一歩が踏み出せないお客様、そもそもデータをどう活用したらよいのか分からないとお悩みのお客様など、データのプロフェッショナルがあらゆるお悩みに対応いたします。
お客様と一緒に、ひとつひとつ課題を紐解いていきますので、お困りごとはございましたらぜひこちらまでお問合せいただければと思います。
今回ご紹介しました「データ基盤構想策定」サービスへのお問合せや、それ以外のお悩みにつきましても、まずはお気軽にご相談ください。