こんにちは、まつきです。dbtは、データアナリストがExtract-Load-Transform(ELT)パイプラインの「変換(Transform)」ステップを実行できるようにするツールです。 この記事では、dbt Labs社より提供されているGitHubリポジトリ「jaffle-shop」を利用してdbtでどんなことができるのか実際に見ていきたいと思います。
※本記事はジール運営のQiitaにも同内容を掲載しております。
目次
1. 事前準備
1-1. dbtアカウント作成
まずはdbtのアカウントを作成しましょう。 https://www.getdbt.com/product/dbt-cloud [Try dbt Cloud free]ボタンでも[Create a free account]ボタンからでも構いませんので、 いずれかをクリックします。
メールアドレス等の情報を入力し、[Create my account]を押下します。
入力したメールアドレス宛にdbtからメールが届きますので、[Verify your email address]をクリックします。
こちらでアカウント作成は完了となります。
1-2. GitHub利用リポジトリの確認
今回利用するGitHubリポジトリのテンプレートを簡単に確認しておきましょう。 https://github.com/dbt-labs/jaffle-shop
1-3. GitHubリポジトリの作成
前段で確認したリポジトリをコピーして、今回利用するGitHubリポジトリを作成します。 今回はGitHubアカウントを持っている前提で記載します。 [Use this template]-[Create a new repository]をクリックします。
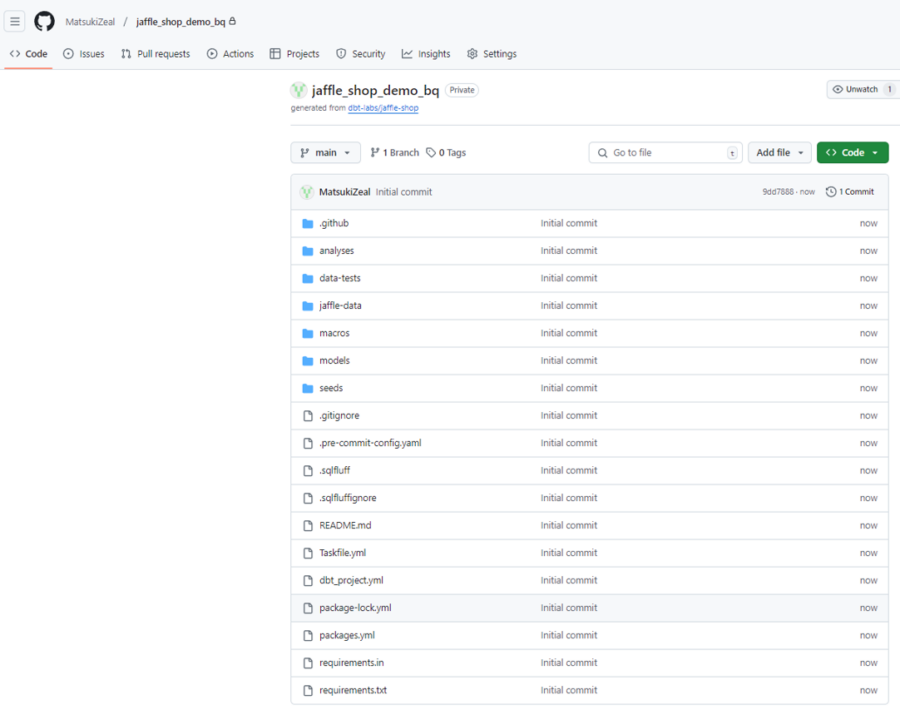
リポジトリ名は任意なので今回は「jaffle_shop_demo_bq」としました。
リポジトリの作成が完了しました。
1-4. BigQuery環境の設定
利用にあたってBigQuryのデータセット作成とサービスアカウント設定を実施します。 今回はGoogle CloudのProjectは既に存在する前提で記載します。 まずはBigQuryのデータセット作成を実施します。 GCPのBigQuery Studioから対象のプロジェクト右の「・・・」から[データセットを作成]をクリックします。
データセットIDは
の二つを作成します。
※画像はdev分のみです。 作成できました。
次にサービスアカウントの設定です。 利用するプロジェクトの[IAM & Admin] – [Service Accounts]をクリックします。
[+ CREATE SERVICE ACCOUNT]をクリックします。
Service account IDを入力します。 今回は「dbt-service」としました。
ロールを付与します。 今回は「Owner」としましたがOwner権限は非常に強いため、留意が必要です。 通常接続には「BigQuery Job User」と「BigQuery Data Editor roles」があれば問題ないかと思います。
作成されたので、サービスアカウントをクリックします。
dbtとの接続設定時に利用するため、サービスアカウントのプライベートキーを作成し、JSON形式でダウンロードします。
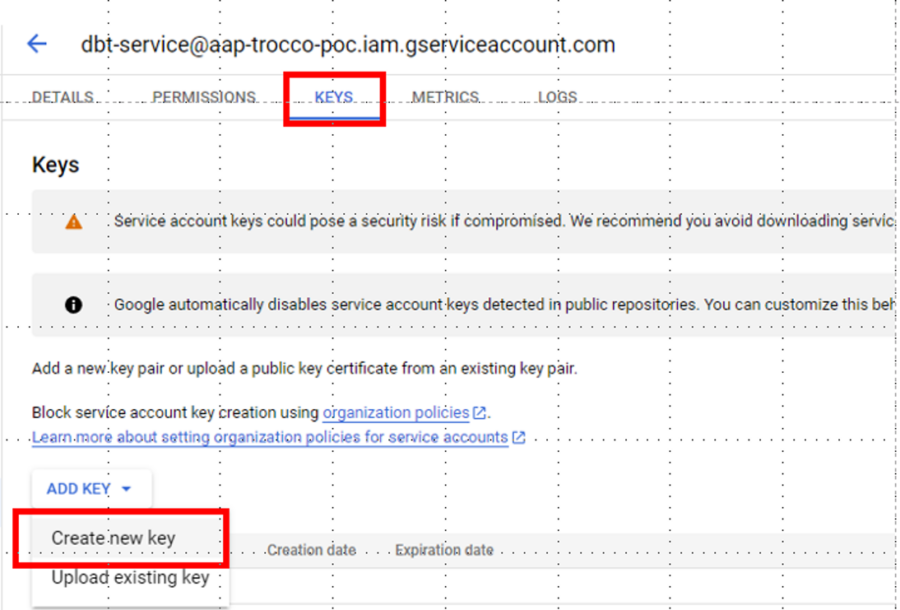
2. 環境設定
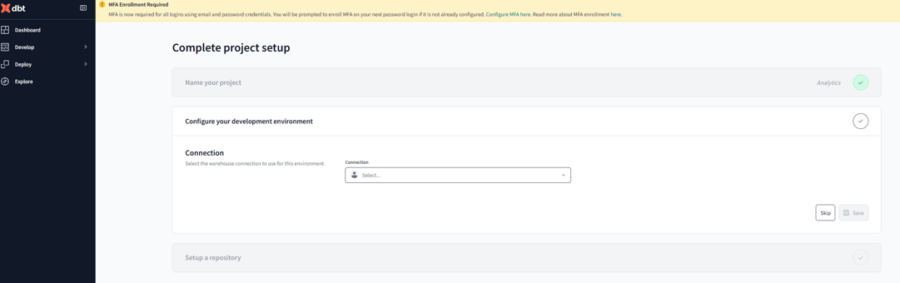
2-1. dbt Cloudで新規プロジェクトを作成
dbt Cloudで新規プロジェクトを作成します。 [Account home]から[New project]を選択します。
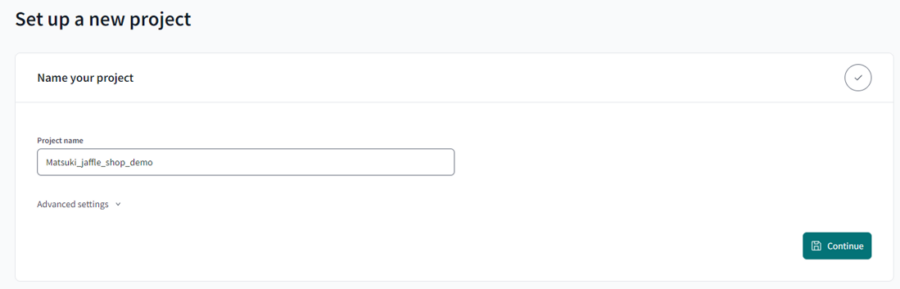
Project name:Matsuki_jaffle_shop_demo を入力して[Continue]を押下します。
2-2. BiqQueryへの接続設定
BigQueryへの接続設定を作成します。 先ほど設定したBigQueryを使うため、[+ Add new connection]をクリックします。
[+ new connection]をクリックします。
BigQueryを選択し、Connection nameを入力したら、[Upload a Serive Account JSON file]をクリックして 先ほど事前準備の際にダウンロードしたサービスアカウントのJSONファイルをアップロードして[Save]します。
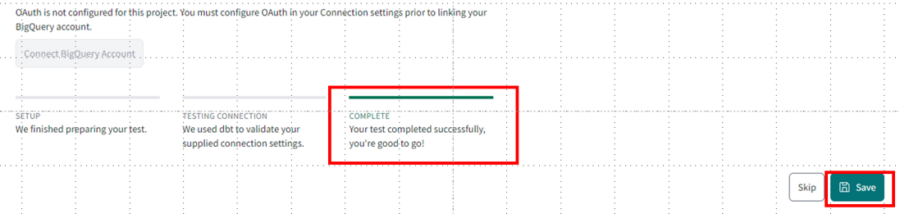
dbtのプロジェクト作成画面に戻り、作成した接続設定を選択します。 Datasetは作成したものを利用するため、「jaffle_shop_demo_bq_dev」としました。 dbt Cloudのプロジェクトを作成する際、デフォルトで開発環境扱いとなるため、devの方を指定しています。 本番環境の設定については後述します。 [Test Connection]をクリックします。
完了したことを確認して[Save]をクリックします。
2-3. リポジトリの設定
こちらは一度スキップしてください。
左側メニューの自分のアカウントから、[Your profile]を選択します。
GitHubの[Link]をクリックします。
[Authorize dbt Cloudをクリックします。
[Configure GitHub Integration]をクリックします。
[Install]をクリックします。
プロジェクト画面の右上[Settings]をクリックします。
[Configure Repository]をクリックします。
[GitHub]-[jaffle_shop_demo_bq]を選択します。
Repositoryが設定されればOKです!
2-4. 本番環境の設定
続いて本番環境の設定を行います。 dbt Cloudではデフォルトで作成したプロジェクトはDEV(開発)環境の扱いとなります。
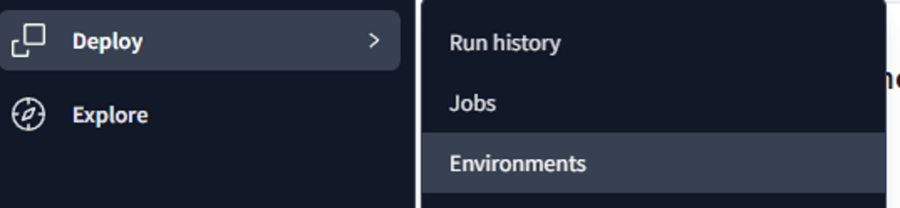
PROD環境を設定するために[Create Environment]をクリックします。 Environment nameを入力し、Connectionを選択してDatasetを入力します。 この時入力するDatasetは事前に作成した
です。
[Test Connection]が問題ないことを確認しておきます。
念のため、Your rofileからデフォルトのデータセットを確認しておきましょう。
Credentialsから先ほど作成したプロジェクトを選択します。
Development credentialsのDatasetが「jaffle_shop_demo_bq_dev」になっていることを確認します。 ※もしなっていない場合、Editで変更してください。
3. dbt でコマンド実行
ローカル環境になりますが、「Chapter 03 とりあえず、dbtを動かしてみる」以降でjaffle-shopの各モデルと処理内容に付いて丁寧に説明されていますので参照してください。 https://zenn.dev/hananah/books/dd9f6f4e82b5d7/viewer/513587
3-1. dbt seed:ソースデータの作成(BigQuery)
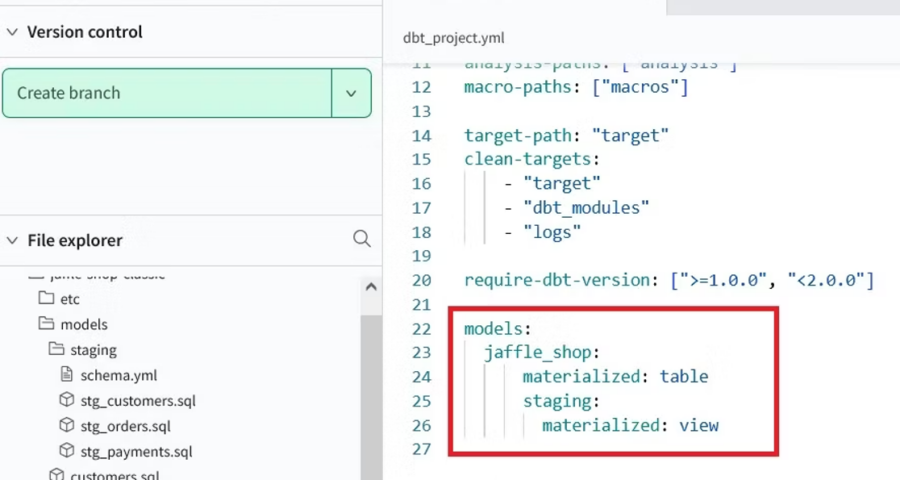
dbt seedコマンドを使って、jaffle-shopの架空データを生成します。 まずは左側メニューバーの[Develop]-[Cloud IDE]を選択し、File explorerからdbt_project.ymlを選択して編集しましょう。 dbt_project.ymlはdbt がどのディレクトリを参照するのかや、どのディレクトリへコンパイルした SQL ファイルをアウトプットするのか、といった設定を記述するファイルです。
15行目に
とありますので、これを
とします。 これでプロジェクトのデータの取り込み元が指定できました。 次に、27~29行目に
とありますので、これを
とします。 これでseedコマンド実行時のデータの出力先を作成したデータセット「jaffle_shop_demo_bq_dev」が指定できました。 dbt seedコマンドを入力し、Enterキー押下で実行します。jaffle-dataフォルダ配下のCSVファイルを読み込み、ファイル名をテーブル名としてBigQueryの開発用のDataset「jaffle_shop_demo_bq_dev」に生成されます。
logを確認する事で、BigQueryのDataset名が確認できます。
BigQuery上でも確認できます。 ※devで実行されているため、prodの方には作成されていません。
データのロードが終了後、後続のコマンド実行時の妨げとなるため、先ほど設定したseed-pathの行と「jaffle-data」フォルダは削除した方が良いです。
3-2. dbt run:モデルの実行
modelsディレクトリに配置したSQLモデルに従ってデータ加工処理を実行するには、dbt runコマンドを使います。 始めにステージング層が実行され、そのあとにデータマート層が実行されます。 (dbtによってDAGや冪等性を考慮され、実行されます)
BigQuery上でも確認できます。
dbt_project.ymlの設定通り、ステージング層はViewで、マート層はTableで作成されます。
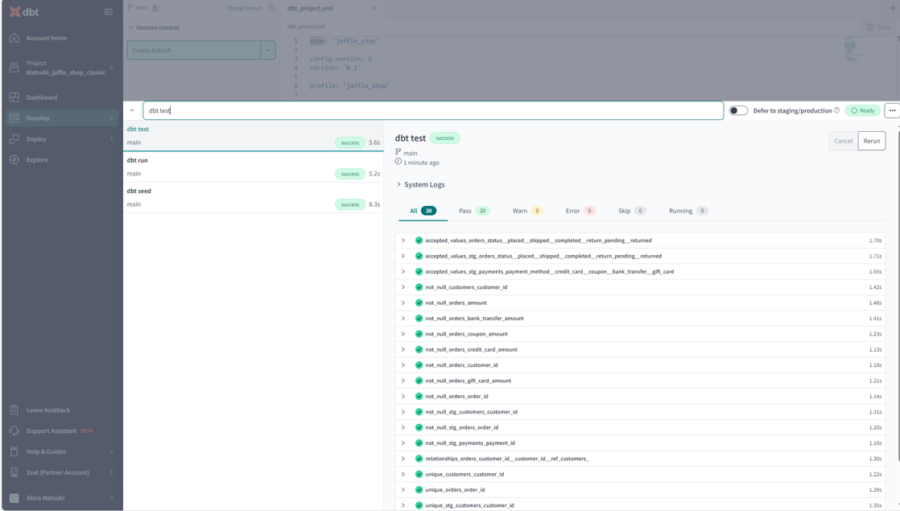
3-3. dbt test:テストの実行
dbt testコマンドでテストの実行を行うことが出来ます。 テストによって品質の低いデータの混入を検知してアラートしたり、データの品質を保ったりするのに使います。 また他にも開発中のデータの前提条件などを明示的に定義するためにも利用できます。
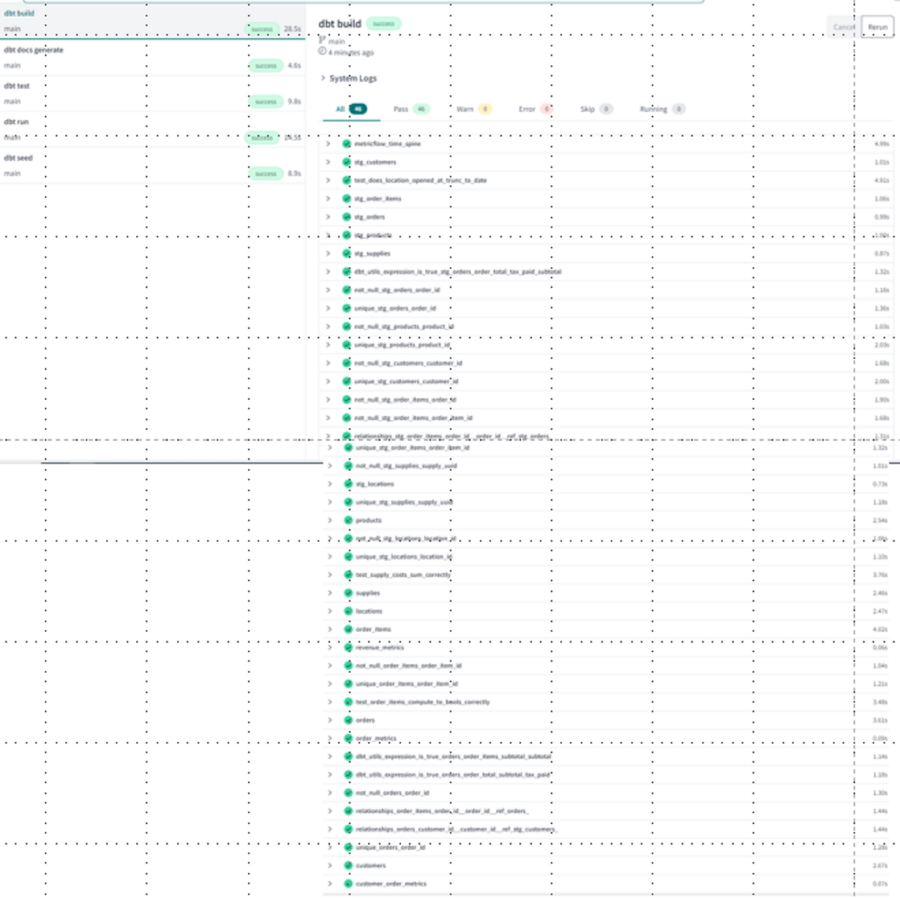
3-4. dbt build:プロジェクトの実行
ここまで3つのコマンドを実行しましたが、それらのコマンドを一括で実行可能なのがdbt buildコマンドです。 都度個別のコマンドの実行が不要なことや、実行順序をdbt側でやってくれるので楽ですね。
3-5. dbt docs generate:ドキュメントを生成
dbt docs generateコマンドで作成したプロジェクトのドキュメントを生成することが可能です。
dbt docs generate実行後、画面をリフレッシュするとdocs viewアイコンが有効になるようです。
例えば、customersテーブルのドキュメントを表示してみます。
右下のアイコンで linege(リネージュ)が表示されます。
最後に
dbt Cloudである程度の基本的な機能を検証してみました。 いかがでしたでしょうか。 次回は本番環境の設定についてもう少し触れていきたいと思います。 今後も検証した内容についてまとめて発信していきたいと思いますので、よろしくお願いいたします。
dbt Cloud ™について製品・サービス概要の詳細はこちらになります。
https://www.zdh.co.jp/products-services/etl/dbt-cloud/TROCCO®について製品・サービス概要の詳細はこちらになります。
https://www.zdh.co.jp/products-services/etl/trocco/
関連記事