2021年8月3日、株式会社ジールにて、『食品・消費財メーカーの成長をAIで促進 ~需要予測・在庫の適正化をデータとAIで実現~』セミナーが開催されました。その内容をレポートします。
はじめに
食品・消費財メーカーでは、かつてない急速な変化に直面しております。需要予測や在庫管理の適正化といった仕組みは、これまでのアナログな手法では変化に追いつけなく、AIを利用したデジタル化が求められているのではないでしょうか。
グローバルの先端企業では、需要予測や在庫の適正化を、データとAIをフルに活用する事で、成功ケースが出てきております。現在、世界でもっとも注目されるデータ&AI企業であるDatabricksは、スターバックスやマクドナルドを始めとしたグローバル先端企業で利用されており、需要予測や在庫の適正化といったAI基盤として活用が広がっております。
本セミナーでは、需要予測と在庫の適正化をテーマに、食品・消費財メーカーなどの製造業での現状を踏まえて、グローバル先端企業でのAI活用事例、ソリューション化されたデモまでをご紹介致します。
目次
第一部:永遠の課題に終止符を打つ! 在庫適正化を実現するデータ活用の秘訣
講師:ウイングアーク1st株式会社 佐野 弘氏
■なぜ、データ活用による効果を生み出しにくいのか?
製造業様においては、ものづくりの過程でさまざまなデータが発生しています。
調達生産、出荷販売という一連の流れに応じて発生するデータもありますし、それ以外にも、勤怠に関するデータ、標準原価に関するデータ、作業指示に関するデータなどをお持ちのお客様もいらっしゃるかもしれません。総務省から発表されたレポートによると、全体の約8割がデータ活用の効果について「どちらでもない」または「多少効果があった」と回答しています。つまり、「充分な効果が得られている」と自信を持って断定しにくい状態と言えそうです。
なぜ効果を生み出せないのか?という点を考えてみると、生産管理においてはデータを収集→蓄積→可視化し、原価低減や、設備の稼働率の向上という効果を狙って投資したとしても、経営サイドにとっては収益に対する貢献度が見えないので投資判断がしにくいと推察されます。
お金の流れについて説明します。基幹系システムから原価に関するデータを最大限に活用して製造原価を下げることが出来れば、利益を高めることができます。同様に、在庫に関するデータを最大限に活用することにより、棚卸資産を下げることができれば分母である総資産を少なくすることができますので、結果的にROA(総資産利益率)を高めることができます。
現場で起きていることが財務成果につながるポイントは、第一に現場と経営をデータでつなぐという発想を持つことです。
■在庫適正化は永遠の課題なのか?
―在庫を持ちたい現場と、在庫を減らしたい経営側―
経営側において、在庫は一時的にお金が姿を変えたものととらえることができます。工場や倉庫に滞留し眠っている在庫は、お金が滞留して眠っている状態ということになります。そのため現場に対して、毎年のように無駄な在庫を削減するように指示を出しますが、一時的に在庫が減るものの、その効果が持続しないという課題があります。
―在庫はたくさんある方が安心である現場側―
現場側においては、製品が欠品した場合、納期の遅延や販売機会の損失になってしまうため、在庫は多く持っていた方がリスクは少ないです。しかし、経営側からは減らす様に指示されます。どの在庫の品目を、どの程度減らせばよいのか、この絞り込みが難しいという課題があります。
<在庫データ活用のポイント>
データ活用のポイントは、2つのステップを推奨します。
① データを活用して機械がある程度絞り込む
② 絞り込んだ後に、人が次のアクションを導き出す
下図は、Dr.SumとMotionBoardという製品を用いたソリューションです。Dr.Sumはデータを蓄えるデータベースで、MotionBoardはデータを可視化するソフトウェアです。本来、Dr.SumとMotionBoardはインストール後、お客様ごとにデータベースの定義を行い、画面を一から作成する必要があるものですが、今回ご紹介する在庫適正化ソリューションは、多数のお客様に事例に基づいて開発したテンプレートです。
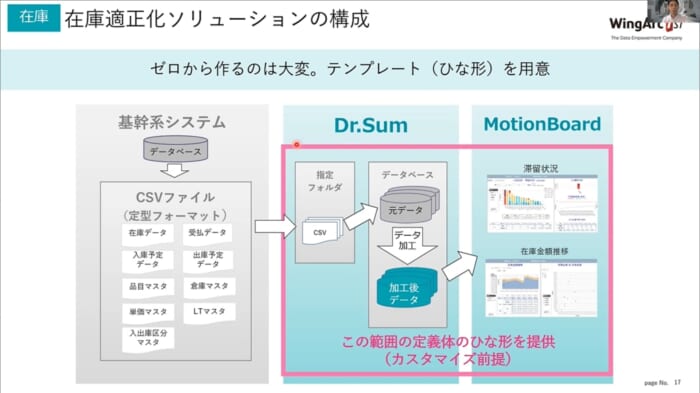
絞りこんで可視化

本来はまっさらな画面ですが、すでに指標が作られているイメージです。このように在庫の可視化を行うと、例えば流動数曲線を見ることによって、在庫が適正かどうかを判断することができます。人間が1つ1つチェックするのは大変ですので、機械的に判定する機能を追加しています。さらに、AIを組み合わせることにより、需要予測や適正在庫数の計算などの可能性が広がります。データを最大限に活用することで、労働生産性を高めることができるようになります。
第二部:世界のAI成功事例の最前線
~米国スターバックス社とマクドナルド社によるAIを活用した需要予測の精度改善とサプライチェーンの最適化~
講師:データブリックス・ジャパン株式会社 竹下 俊一郎氏
■コロナ禍での小売業が成長する4つの柱
2020年~2021年、かつてない程の不確実性に直面しており、外出の自粛や工場の操業停止などパンデミックに基づく影響というのは計り知れません。今回は、この状況下で成長を続ける小売業のデータ部門、AIに関する下記の4つの柱を例にご紹介します。
① ロイヤリティと顧客離反への大きな変化
② サービスにかかるコストの削減
③ 購買チャネルのデジタル移行/体験強化
④ データとAIを用いてビジネス判断の俊敏化

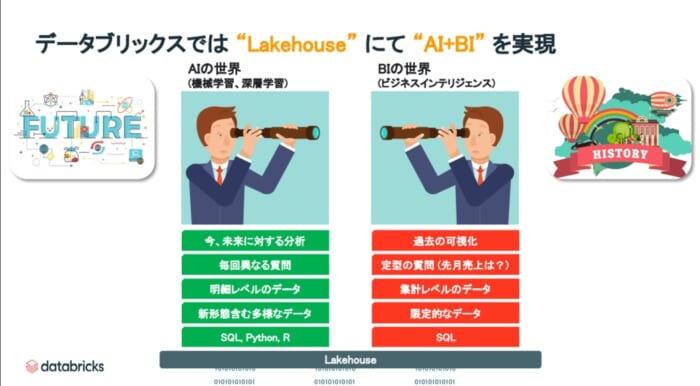
■データブリックス Lakehouse にて AI+BI
データブリックスは、データとAIに特化しておりLakehouseというプラットフォームで提供しています。BIの世界では、どちらかというと過去の可視化をフォーカスしていました。機械学習AIの力を借りると、未来に対する分析をさらに付け加えることができます。集計レベルにおいて、エリア別の予測にとどまっていたところを明細レベルへ、商品レベルにおいて、店舗情報をリアルタイムレベルへときめ細やかに分析を行います。多様なデータということで、POSデータのみならず、新しい店舗の情報、もしくは動画の情報などを組み込みながら、より精緻なモデルを実現します。
▶ユースケース1/スターバックス
<背景>
スターバックスの店舗を見渡すと、さまざまなAIのサービスが裏に組み込まれています。需要予測やレコメンデーションエンジン、背後には 在庫管理、陳列の状況や人の動きを動体検知するなどのコンピュータ・ビジョンがあります。スターバックスは、店舗での買い物、もしくはECデリバリー、ドライブスルーなど、『お買い物体験』が多角化し、マルチチャンネル化している状況です。そのため、お客様の需要が非常に読みづらくなっていました。

<課題>
① データサイロ・・・ほしいタイミングでほしいデータにアクセスできなかった
② ツールサイロ・・・ツールの分散によりチームとして目的に対して向かい合えなかった
③ 管理のサイロ・・・オンプレミス(自社の環境)を利用していたが、コンピューターのリソース不足
④ リアルタイム性 ・・・オムニチャネルでのデータの鮮度、天気のデータ、IoTデータ、競合の価格
⑤ 高速処理とデータ管理・・・増え続けるデータの中で振り返りが重要であり、適切なタイミングでスナップショットをとらなければならない
⑥ 精緻な予測・・・機械学習モデルにおいて、日時単位、店舗単位、SKU単位データの取得
<Databricks導入により解決>
Before➡After

製造小売業は、一社で成り立っているわけではありません。サプライヤ―や流通業、ブローカーなどさまざまなグループ会社もしくはパートナー会社とビジネスを行っています。その対応は、データシェアという考え方に基づいてデータのプロバイダ、例えば小売業データの利用者、物流業などとリアルタイムにデータを連携します。そういった点で最適な在庫管理、もしくは需要予測を一体感を持って取り組んでいる大きなユースケースです。
▶ユースケース/マクドナルド
<背景>
マクドナルドは、バリューチェーンを少し抽象化したものです。生産者があり、そしてサプライチェーンがあり、配送、レストラン、オペレーション、ドライブスルー、配達、消費者で成り立っています。各パーツにおけるデータとAIをマクドナルドは活用しています。スターバックスと近しいところで、需要予測でパーソナライズやクロスチャンネルの市場でのパフォーマンス測定、様々なお客様接点のデータを集めて各種施策のパフォーマンスを測り、発注プロセスの自動化を行っています。
またコンピュータ・ビジョンに基づいて走っている車など、動いているものを検知して何らかの業務プロセスに活かそうという取り組みを行っています。マクドナルドの場合、カメラが店舗の近くについており、ドライブスルーに入る車、歩行中の人を検知し、データとAIによるサプライチェーンの変革を行っています。
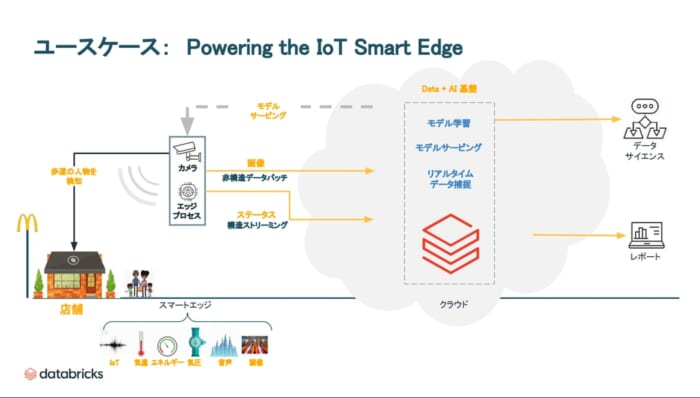
<課題>
以前は、集計<aggregation>での予測をしていました。商品カテゴリー別もしくは商圏エリア別、週別などは、どんぶり勘定の需要予測でした。各地に点在する店舗は、ビジネス街や住宅街などエリアによって大きな特徴があり、個別の店舗にとっては集計別の予測は限界がありました。企業として、全店舗が同様に動作することが課題に上がっていました。
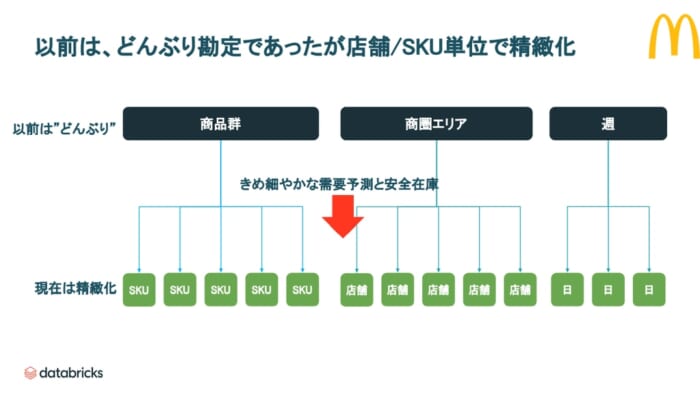
<現状と効果>
分析の深さにおいて、これまでエリア別の分析や、商品カテゴリー別の分析を行っていましたが、店舗別やSKUなどのきめ細やかな明細レベルで分析を行うことになり、精度が非常に上がりビジネス成果をもたらしたとのことです。さらにスピードの面が向上し、早期なビジネスアクションに繋がりました。また360°ビューにより、機械学習とデータの活用が推進し頑健なサプライチェーンが実現しました。

もともとは商品のカテゴリー別で国ごとにひとつの予測を行っていたところから、商品別、店舗物、さらには一日(朝・昼・夜)を通した傾向を把握し、きめ細やかな予測を打ち出しています。スターバックスとマクドナルドのユースケースは、非常に統合された予測サービスを行い、BIに反映することで、BIとAIの要素が加わり発注の改善、労働力のスケジューリング、食品ロスの改善に取り組んでいるというご紹介でした。
Databricksでは、きめ細やかな需要予測を含めて、データを用いて、様々なロジックを検証した結果、どのような効果が期待できるのかをパッケージ化しております。導入も含めてご検討頂ければと思います。
第三部:DatabricksとMotionBoardを利用した「需要予測」と「安全在庫」の実装ケーススタディ
講師:株式会社ジール
栗原 和音氏
池 守垠氏
■デモの概要
今回は下記のユーザとニーズを想定し、サンプルデータを用いてデモを実施しました。
<想定ユーザ>
全国展開するスーパーの店長
<ニーズ>
-
需要予測:来週の売上げを予測したい
-
安全在庫:予測した売り上げに対し、適切な在庫を持ちたい
<データ>
-
店舗ごと/商品ごとの売上数量、金額
-
天気データ
-
カレンダーデータ
今回のデモは、Azureに存在するDatabricksをMotionBoard Cloudから参照するしくみです。
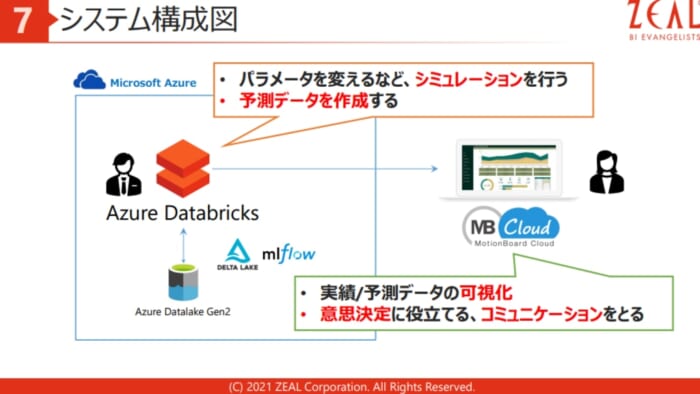
●2つの製品の役割
・MotionBoard Cloud
元々存在していた実績データにDatabricksで作成した予測データを加えて可視化することで、意思決定の促進やコミュニケーションの活性化を図ります。
・Databricks
パラメーターを変えるなどしてシミュレーションを行い、そのシミュレーションによって予測データを作成します。Databricksは高性能最先端で敷居が高い製品という印象を持っている方もいらっしゃるかもしれませんが、ソリューションアクセラレータにより機械学習のハードルを下げる支援を行っています。ソリューションアクセラレータの具体的な支援内容は下記の通りです。
-
データサイエンスに関するスキル不足や人材不足を解消するために、カスタマイズして使えるパッケージを提供
-
データ知識と業務知識のどちらか一方しかない方にも使いやすいように、ユーザのユースケースを展開
-
PoCにとどまらず実運用まで進めるために、優先度の高い業界共通の課題に注力
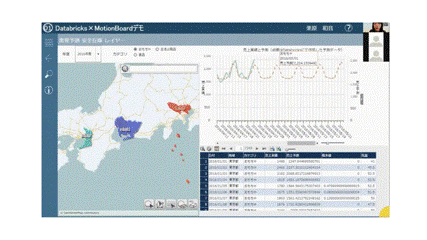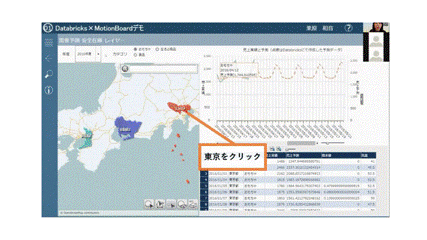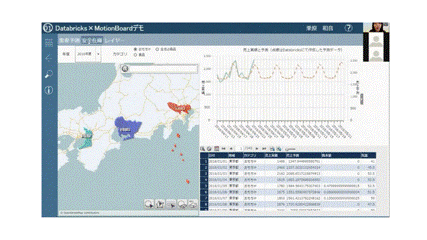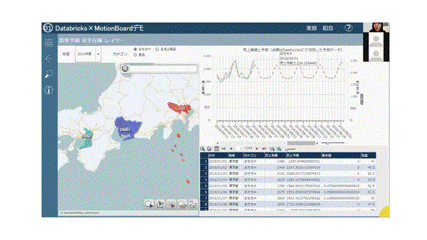
MotionBoard Cloud画面
※画像ファイル形式を変換したことにより、画像が荒くなっております。
まず、MotionBoardの画面です。
左にある地図データは、東京、愛知、大阪に色がついております。赤い色ほど売り上げが高いもので、青色ほど売り上げが低いものとなっており、直感的に売り上げが高い地域がわかるようになっております。さらにこの東京が赤くなっているためクリックしてみると、データが絞り込まれます。
上の折れ線グラフに注目いただくと、赤い点線と緑の実線があります。緑の実線は売上実績、赤い点線は予測値として、未来のデータが表示されています。こちらの点線がDatabricksによって作成した予測データです。
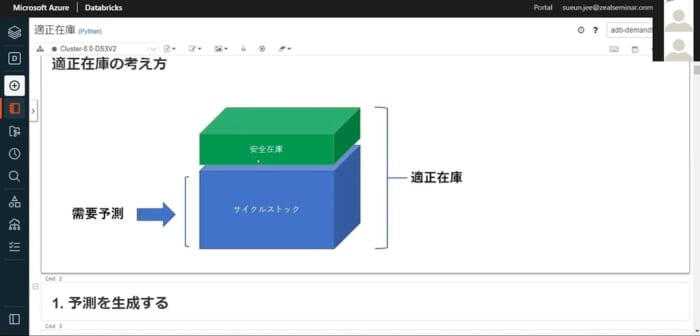
Databricks画面
次に、Databricksの画面です。
デモの前に適正在庫について説明します。適正在庫とは、サイクルストックに安全在庫をバッファーとして積み上げたものです。サイクルストックは、需要予測の結果から算出することができます。
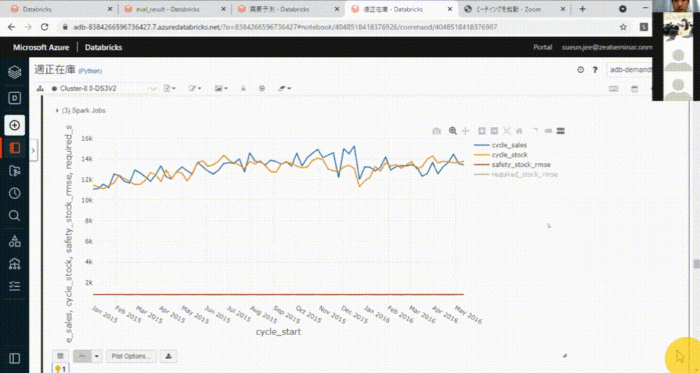
青いラインが売上実績値、オレンジのラインが需要予測です。売上実績値を表す青いラインが需要予測を表すオレンジのラインを越えてしまうところが多々あり、これでは在庫切れを発生させてしまいます。緑色のラインは、需要予測に安全在庫を積み上げた適正在庫を表しています。適正在庫を表す緑のラインを見ると、売上実績値を表す青いラインが緑のラインを超えるところがかなり減ったことがわかります。その結果、在庫切れを防ぐことができます。
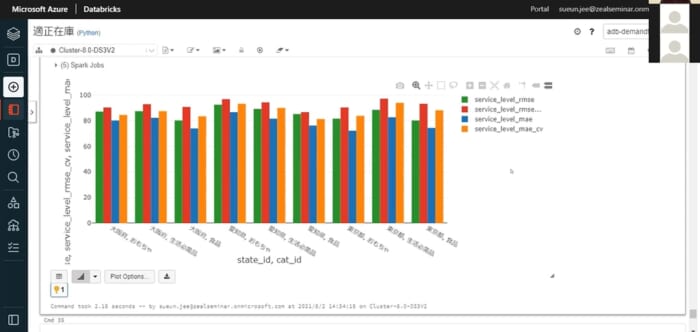
そして"どのシミュレーション値を使えばベストな適正在庫を算出できるのか" ということも調べることができます。
上記のグラフは、Y軸がサービスレベルになっていて、サービスレベルが高いほど在庫切れになる可能性が低いことを表しています。調べてみると、商品カテゴリーや店舗など、どの切り口の組み合わせでも赤い棒グラフのサービスレベルが1番高いことがわかります。よって、今回のシナリオに関しては、赤い棒グラフで表示されているシミュレーションの値を使って適正在庫を算出すると、ベストな結果が得られるという結論になります。

まとめ
DatabricksとMotionBoard の製品導入以前は、一部のスキルの高いデータサイエンティストが行っていたことが、製品導入後、データサイエンスがより簡単に機械学習を活用することができるようになり、ユースケースを参考にシミュレーションのパターンを増やすことが可能になりました。そしてMotionBoard Cloudを導入することで、データサイエンティストやマネージャーが、現場と同じデータを同じタイミングで共有できるようになり、アクションにつなげやすくなったという効果が期待できるようになります。
在庫管理に課題を感じている、機械学習に興味があるが、何から始めて良いかわからない、もしくはDatabricksやMotionBoardの製品について詳しく知りたい方は、是非弊社にお問い合わせください。
▶Databricks
https://www.zdh.co.jp/products/databricks/
▶MotionBoard
https://www.zdh.co.jp/products/motionboard/